victoriaLogs
2026年4月6日 · 3806 字 · 更新 2026年4月6日 · 24 阅读
victoriaLogs介绍
VictoriaLogs是一款资源高效、速度快 、轻量级、无模式、零配置(单二进制)的日志数据库。相比传统ELK,victoriaLogs更轻量,占用资源更低。相比Loki,victoriaLogs查询速度更快,对乱序日志更友好
victoriaLogs架构
victoriaLogs的设计哲学非常简单:“尽量减少组件,用高效的数据结构解决问题”。其架构图如下所示:
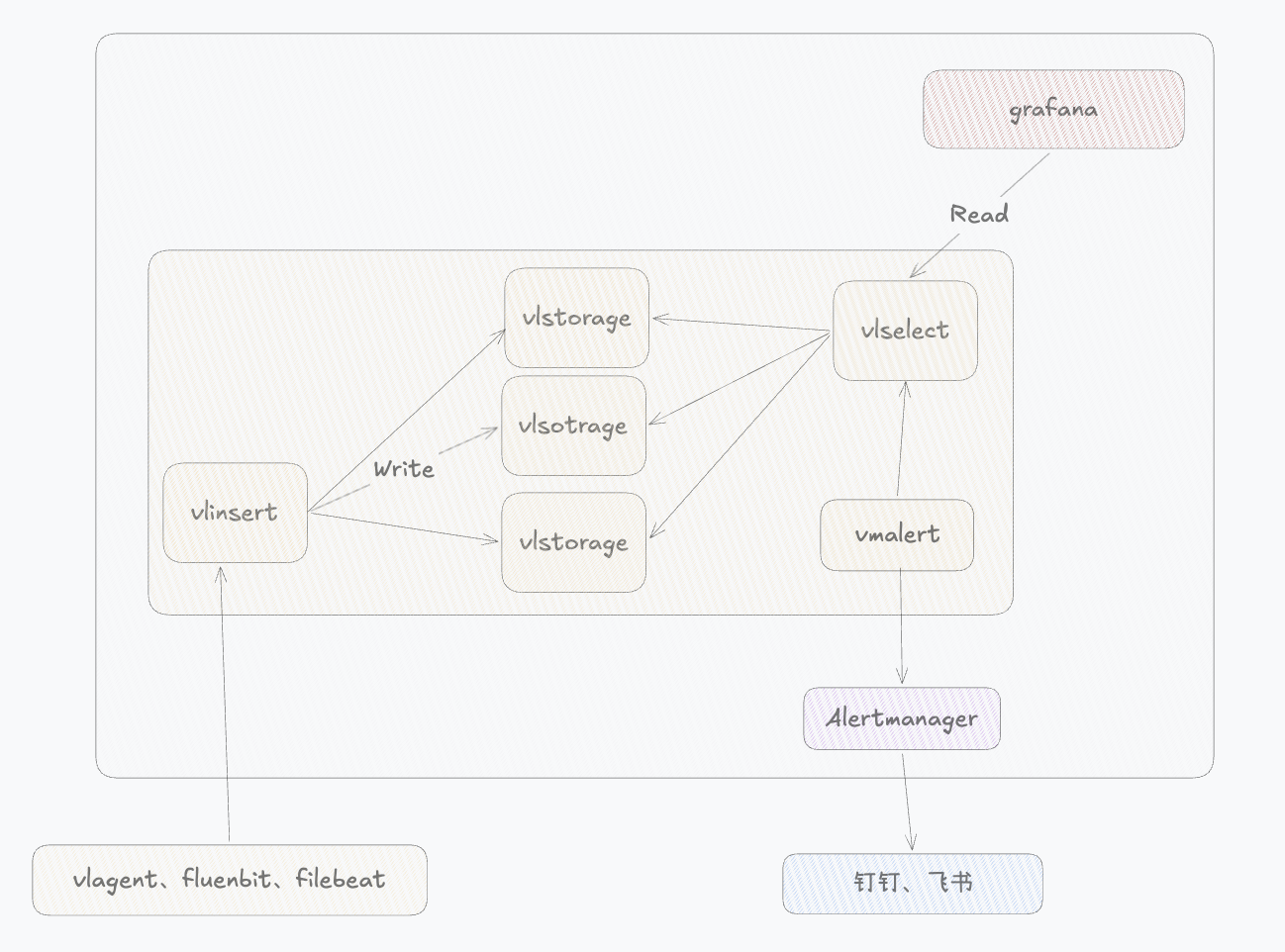
可以看到,victoriaLogs的核心组件主要有四个:
- vlinsert:是整个系统的写入网关。主要负责日志写请求、解析日志数据,对日志进行格式化处理后再分发给后端vlstorage
- vlstorage:主要负责日志数据落盘、构建索引,并对日志进行压缩
- vlselect:是整个系统的查询层。主要负责接收用户请求,解析查询语句,并从多个vlstorage节点拉取数据,再进行聚合并返回结果
- vlagent:是一个轻量级日志采集组件,用于从各种数据源收集日志
victoriaLogs部署方式
victoriaLogs的所有组件都在一个二进制文件中,默认的部署方式为单节点部署。单节点实例可进行垂直扩展,在极限优化下,也能处理TB级/天,甚至更高的数据量。
如果单节点victoriaLogs达到可拓展限制,你可以通过切换到集群部署来进一步拓展。集群模式通过将系统分为三个角色来实现水平拓展:vlinsert、vlselect、vlstorage。
所有这些角色本质上仍然是同一个二进制文件,区别仅在于启动方式时使用了不同的标志。
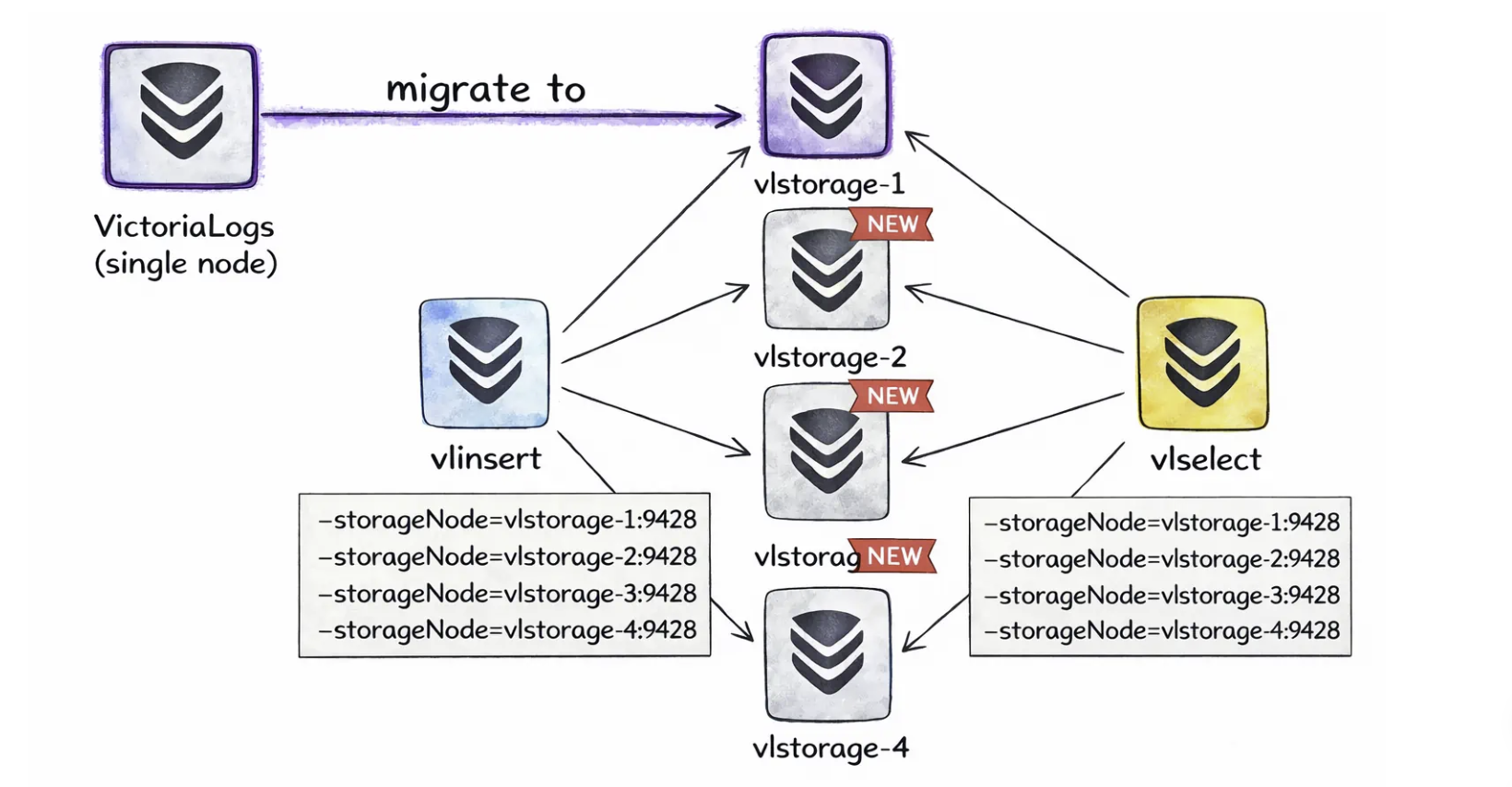
如上图,从单节点切换至集群非常简单。你可以保留现有的单节点victoriaLogs(vlstorage-1),再部署多个storage实例,并启动一个或多个vlinsert/vlselect实例即可。
需要注意的是,victoriaLogs和victoriaMetrics在架构设计上有一个非常显著的区别。在victoriaMetrics集群中,vminsert会负责把数据写到N个vmstorage中,这是存储系统内部实现的数据复制。而在victoriaLogs中,vlstorage节点之间是完全独立的,它不提供存储层自动同步数据的功能。如果需要实现高可用,必须在采集端(如vlagent)实现。
victoriaLogs之所以这样设计,是因为日志系统的目标和指标系统完全不同:
- 日志量通常会非常大,如果在存储层复制,成本会很高
- 日志系统更关心写入吞吐量,而不是数据严格一致(丢几条不致命,重复也可接收)
核心概念
数据模型
victoriaLogs在日志摄取过程中,会将多级JSON(嵌套JSON)转换为单级JSON。为了简化搜索,数组、数字和布尔值会被转换为字符串。除此之外,字段名和字段值可以包含任意字符,但Unicode字符必须使用UTF-8编码。例如下面的JSON日志:
{
"host": {
"name": "foobar",
"os": {
"version": "1.2.3"
},
"other": {
"offset": 12345,
"is_error": false
}
}
}会被转换成
{
"host.name": "foobar",
"host.os.version": "1.2.3",
"host.other.offset": "12345",
"host.other.is_error:"false"
}victoriaLogs会自动为所有导入的日志中的所有字段建立索引,这使得所有字段都能进行全文搜索。除了其它任意字段外,victoriaLogs还支持以下特殊字段:
- _msg
- _time
- _stream、_stream_id
_msg字段
victoriaLogs要求每条被摄取的日志至少包含一个_msg字段,它包含了实际的日志消息。例如,以下是victoriaLogs中的最小日志条目:
{
"_msg": "some log message"
}如果实际日志消息中使用的字段名称不是_msg,则可通过HTTP查询参数_msg_field或HTTP标头VL-Msg-Field在数据摄取期间来指定。例如日志消息位于event.original字段中,则可以指定查询参数_msg_field=event.original。如果尝试从_msg_field获取信息后_msg字段仍然为空,victoriaLogs会自动将其设置为通过命令行标志-defaultMsgValue指定的值。
如果日志条目的必要信息在其它字段中,则_msg字段为空也是可以接受的,而空的_msg字段会填充为-defaultMsgValue,这对于处理和查询来说非常轻量级。
_time字段
摄入的日志中可能包含一个_time字段,表示该日志条目的时间戳。此字段必须使用ISO8601/RFC3339或Unix时间戳等格式
{
"_msg": "some log message",
"_time": "2023-04-12T06:38:11.095Z"
}如果时间戳使用的字段名不是_time,也可以通过和_msg一样的方式来指定,只是HTTP查询参数和HTTP标头换成了_time_field和VL-Time-Field。另外,如果该字段在指定后仍然为空,则会以数据摄取时间作为填充。
_stream字段
某些结构化日志的字段可以用来唯一标识生成该日志的应用程序,这种字段可以是单个或多个。victoriaLogs会将这种单个应用程序的日志构建成一个流,这样可以提高压缩比并减少磁盘占用。并且在按流字段进行搜索时需要扫描的数据量也会变少,查询性能也会得到提升。
因此,每个被摄取的日志条目都应该关联到一个日志流上,每个日志流包含以下特殊字段:
- _stream_id:这是日志流的唯一标识符,可以通过
_stream_id过滤器选择特定流的所有日志 - _stream:此字段包含用来构建流的字段,格式类似于Prometheus指标中的标签集
{
"host": "host-123",
"app": "my-app"
}如果将上面的host和app字段与流关联,则该流的所有日志条目都应该包含着两个字段。而该流的_stream字段的值则是{host="host-123",app="my-app"}。默认情况下,_stream字段的值为{},因为victoriaLogs本身无法自动确定哪些字段可以用来表示标识一个唯一的流,这可能会导致资源利用率和查询性能不佳。因此,建议在数据摄取期间通过_stream_fields查询参数来指定用来构建流的字段。
{
"kubernetes.namespace": "some-namespace",
"kubernetes.node.name": "some-node",
"kubernetes.pod.name": "some-pod",
"kubernetes.container.name": "some-container",
"_msg": "some log message"
}对于以上日志,在数据摄取期间可以指定:
- _stream_fields=kubernetes.namespace,kubernetes.node.name,kubernetes.pod.name,kubernetes.container.name
以便将每个容器的日志正确存储到不同的流中。
拓展
每个被摄取的日志条目除了_msg和_time等字段外,还可以包含任意数量的其它字段。例如level、ip、user_id、trace_id等。这些字段也会被用来构建索引,从而简化和优化搜索查询。
通常情况下,直接搜索trace_id字段会比在冗长的日志消息中搜索trace_id更快。例如,trace_id:="XXXX"查询通常比_msg:"trace_id=XXXXZ"查询更快。这是因为用trace_id构建的是专用倒排索引,用来精准匹配。而_msg中的内容会进行分词再构建为全文索引,一般用来模糊匹配。具体的后面再做详细介绍。
核心概念
流
victoriaLogs既可以接收结构化日志也可以接收非结构化日志。例如下面的非结构化日志:
127.0.0.1 - frank [28/Jul/2025:10:12:07 +0000] "GET /apache.gif HTTP/1.0" 200 2326
Jul 28 10:12:04 web-01 sshd[987]: Accepted publickey for root from 192.0.2.7 port 51122 ssh2
2025-07-28 10:15:09,123 ERROR main MyApp - java.lang.NullPointerException: Foo.bar(Foo.java:42)这些日志行都没有被拆分成明显的键值对,因此从日志记录的角度来看,它们是非结构化的。victoriaLogs会将第一条日志转换成下面的结构化日志:
{
"_msg": "127.0.0.1 - frank [28/Jul/2025:10:12:07 +0000] \"GET /apache.gif HTTP/1.0\" 200 2326",
"_time": "2025-07-28T10:12:07Z"
}在victoriaLogs中,流是一个逻辑上的桶,其中包含所有彼此相关的日志。如下,一个payments服务的日志:
{
"service": "payments",
"_time": "2025-07-28T10:20:14Z",
"_msg": "received transfer request id=12345"
}这条日志的service会作为流字段,这样来自同一服务的所有日志都会被放入同一个存储桶(日志流)中。数据库为将该流的日志一起写入磁盘,并将它们压缩成块。也就是说,同一个日志流的日志会存储在相同的块中。
在查询时,系统在查询时可以通过流字段快速过滤掉不属于该流的数据块,从而提升查询效率。例如,可以使用LogsQL流过滤器查找payments服务服务的日志:
$ _time:1h {service="payments"} level:="error" "paid"该查询只会检查包含流payments的数据块。之后,会再扫描这些数据块,根据查询中的其他筛选条件查找相关日志。因此,再选择流字段时,尽量包含最常用的用于过滤日志的字段,例如app、instance或namespace,前提是它们的值不会频繁更改。
粗流
这里接着一上面payments服务的日志举例。当只选择service作为流字段的时候,假设该流每秒有一万条日志,那么这种单字段流很快就会暴露出它的第一个缺点。一小时内,payments服务会产生3600万条日志,在这3600万条日志中找到所需的日志是一项CPU密集型任务,速度会非常慢。而且整个数据库将包含大量的来自该流的数据块,这就是“数据流过大”的问题。
最直接的解决方式是,通过添加更多的流字段来拆分数据流。例如,在流字段中添加pod字段,查询语句将如下所示:
$ _time:1h {service="payments", pod="payments-6c7df89kx"} level:="error" "paid"这样,只会扫描包含流{service="payments", pod="payments-6c7df89kx"}的块,从而大大减少了扫描时间。
高基数流
虽然可以通过添加更多的流字段来解决流过大的问题,但也可能会导致第二个更棘手的问题:“高基数”。假设你在日志流中添加了一个user_id字段:
$ _time:1h {service="payments", user_id="johndoe"} level:="error"此时,如果payments服务在一小时内处理了数百万个用户的请求,日志中就会产生数百万个不同的user_id。这也会导致数百万个流被构建,数据库中也会生成数百万个数据块。当查询关于{service="payments", user_id="johndoe"}的日志时,需要遍历这些数据块,然后再扫描符合条件的数据块。
高基数字段名
还有第二种更隐蔽的高基数变体,那就是字段名称本身不断变化。如下所示:
{
"_msg": "page viewed",
"user_id": "u-347912",
"campaign": "summersizzle",
"sku_00000001.clicks": 1,
"sku_00000001.hover_ms": 83,
"sku_00000002.clicks": 0,
"sku_00000002.hover_ms": 12,
//...
"sku_00100000.clicks": 3,
"sku_00100000.hover_ms": 57
}这也会导致高基数流的问题。
存储
victoriaLogs摄取的日志会存储在<storageDataPath>/partitions/目录下的按天划分的子目录(分区)中。这些按天划分的子目录会以YYYYMMDD格式命名。例如,名为20250418的目录包含_time字段值为2025年4月18日UTC的日志。这种方式便于更地灵活管理数据。
保留策略
victoriaLogs的数据存储在本地文件上,目前暂不支持对象存储。默认情况下,数据会保留7天,可以通过-retentionPeriod命令行标志来进行配置。
上面介绍过,摄取的数据会按天分区,每个日志分区是一个目录,它会自动删除超出配置保留期限的分区目录。如果接收的新日志时间戳超出了配置的保留期限,victoriaLogs也会在数据摄取阶段自动丢弃这些日志。
默认情况下,victoriaLogs不接受时间戳大于两天后的日志条目,若需要接收时间戳更大的日志,可使用-futureRetention命令行标志指定所需的"未来保留期限"。
按磁盘空间使用情况
victoriaLogs可以根据磁盘空间使用情况来自动删除较旧的每日分区,有两种方法可以选择:
- -retention.maxDiskSpaceUsageBytes:绝对磁盘空间限制。如果数据总大小达到了该标志设置的限制值,则删除旧的每日分区
- -retention.maxDiskUsagePercent:基于百分比的磁盘空间限制。如果数据总大小超过了该标志设置的百分比,则删除旧的每日分区
victoriaLogs通常会将日志压缩10倍或更多。这意味着,当设置磁盘最大可用为100GiB时,它可以存储超过1TB的未压缩日志。
总结
victoriaLogs会将嵌套的JSON对象打平,让每一条日志在存储层看起来都是一组简单的键值对,所有被打平的键值对都会进入索引。_stream是由标签组成的集合,属于同一个stream的日志物理上存放在一起,这样同一个服务中,格式高度相似的日志能提高压缩率。而_msg用来存放原始日志或主要文本,victoriaLogs会对其进行分词,并构建全文索引,但处理方式比ES轻量很多,传统ES会为每个字段维护一个巨大的词典和倒排列表,这会导致索引膨胀。
_stream和其它字段构建的索引用于精准匹配,而_msg分词后得到的字段构建的索引用于模糊匹配。此外,victoriaLogs使用了稀疏索引和布隆过滤器,查询时可以先通过布隆过滤器快速排除掉肯定不包含该关键词的数据块,大大减少了磁盘I/O。
即使是全字段索引,利用现代CPU的SIMD指令集也可以进行快速扫描。相比于维护复杂的树状索引结构,直接在内存中对压缩后的列数据进行暴力扫描,往往比查找复杂的倒排索引更快。
对比Loki
victoriaLogs目前只支持本地磁盘存储,不支持对象存储作为后端。这意味着如果你的环境在云上,成本可能会比较高。另外,对grafana生态的支持没有loki友好。
loki只索引标签,不全面索引日志内容,查询时需要在匹配标签之后扫描文本片段来查找匹配行。这意味着,虽然标签过滤很快,但当查询需要全文搜索或范围广的匹配时,性能会下降很多。
victoriaLogs对日志做了更全字段索引与更高效的存储设计。对日志的各个字段都会进行索引,而不仅仅是标签。并结合了布隆过滤器等技术来加速搜索,就算针对高基数字段也支持高效查询。这使得复杂查询、全文搜索和高基数字段过滤都能很快响应,同时它的存储和压缩设计也允许更小的存储空间和更低的CPU/内存占用。