监控系统基础概念
2026年4月6日 · 3541 字 · 更新 2026年4月7日 · 31 阅读
时间序列和样本
metric_name{job="api", instance="a"} 123.45 1690000000000- 时间序列:由一个唯一的指标名称和一组键值对标签组成
- 指标名称:metric_name
- 键值对标签:a
- 样本:由一个时间戳和value值组成
分辨率
分辨率是时间序列的样本之间的最小间隔
----------------------------------------------------------------------
| <time series> | <value> | <timestamp> |
| requests_total{path="/health", code="200"} | 1 | 1676297640 |
| requests_total{path="/health", code="200"} | 2 | 1676297670 |
| requests_total{path="/health", code="200"} | 3 | 1676297700 |
....上面时间序列中,每30s更新一次值,这意味着它的分辨率也是30s。在pull模式下,分辨率等于抓取时间,并由监控系统控制。push模式下,分辨率时样本时间戳之间的间隔,由客户端(指标收集器控制)。应尽量保持时间序列的分辨率一致。
回溯窗口
系统在执行语句查询时,经常会用到rollup函数。此类函数都需要一个时间维度上的回溯窗口,比如increase函数用于计算某个指标在指定时间范围内的增量,那就必须在语句中指定出明确的时间范围,这个时间范围就是一个回溯窗口。
increase(requests_total[3m])上面的3m就是回溯窗口,告诉监控系统汇总出request_total指标的原始样本值在3分钟内的增加量。有时因为用户并不清楚某指标的样本粒度,可能会给出错误的回溯窗口。比如increase(requests_total[1s]),要求汇总requests_total指标1s内的增量,但数据库的raw sample粒度是30秒一个数据点,在这1秒的时间范围内可能一条数据都没有,无法给出结果。
指标类型
一共有四种指标类型,每种类型都有不同的用途和存储方式:
- count计数器:单调递增的累积指标,只增不减,只能通过重启进程重置为零。适用于衡量时间发生次数
- gauge计量器:可增可减的指标,反映了某一时刻的瞬时状态值,其值可以任意上下波动。主要用于直接查询当前值,或计算变化量
- histogram直方图:用于对采样点(通常是请求持续时间或响应大小)进行统计聚合的指标。适用于衡量服务的延迟或请求大小分布,如P95、P99延迟
- summary摘要:类似于直方图,也用于采样点的统计聚合,但其分位数是在客户端计算并暴露的。适用于精确计算单个实例的分位数,但聚合查询较少或不需要严格精确度的场景
经典直方图
经典直方图并不是一个“真正的单一数据结构”,而是由多个时间序列组合而成。其数据结构如下:
http_request_duration_seconds_bucket{le="0.1"} 5
http_request_duration_seconds_bucket{le="0.2"} 12
http_request_duration_seconds_bucket{le="0.5"} 20
http_request_duration_seconds_bucket{le="+Inf"} 25
http_request_duration_seconds_sum 2.3
http_request_duration_seconds_count 25
# 需要注意,桶是累积的,也就是说le=0.2的桶里可能包含了le=0.1的数据如上,数据被分散存储在N+2(这个2就是sum和count)个不同的TSDB时间序列的chunk中。每个桶(le="x")都被视为一个独立的、带有唯一标签集的时间序列。prometheus会为每个时间序列分配一个Series ID,这些时间序列的数据被压缩并存储在各自的chunk中。
原生直方图
是一个真正的单个直方图时间序列。整个直方图(包括所有桶、总和、总数)被视为一个时间序列,只需要为这个直方图分配一个Sereis ID,所以对应的样本数据也被尽可能的集中存储在一个chunk中,且chunk内部存储的不再是float或int值,而是高度压缩的、自适应的直方图数据结构(包含对数桶信息)。因此原生直方图在存储效率和查询性能上都有显著提升。
P95、P99就是基于直方图进行计算的
向量查询
一般查询的时候可以返回四种不同类型的数据:即时向量、范围向量、标量和字符串。如下:
node_cpu_usage
// 查询结果:每个时间序列对应一个样本值
node_cpu_usage{instance="server1"} 0.6
node_cpu_usage{instance="server2"} 0.7当直接使用指标名称进行查询时,它既不是即时查询也不是范围查询,而是即时向量选择器。这种表达式本身总是返回一个即时向量,即在某一时间点上,每个时间序列对应一个样本值。是否执行为“即时查询”或“范围查询”,取决于查询的执行方式。例如,在 Prometheus API或Grafana中,可以通过指定时间范围,将同一个表达式按时间步长多次评估,从而得到时间序列数据。这种情况下,表达式虽然仍然是即时向量选择器,但整体查询结果表现为范围查询。那即时查询和范围范围又是什么呢?
- 即时向量:按某个时间点获取某个指标的最新样本值,通常用于查看当前状态
- 范围向量:查询某个指标在一段时间内的变化情况,它会返回该时间段内的多个样本值,并允许你查看指标随时间的变化情况,通常以图表的形式呈现
即时向量
即时向量是一组时间序列,其中每个时间序列只有一个样本,即查询运行时的最新值。如在15:30运行node_cpu_usage,它将返回最接近但不晚于15:30的样本。由于即时查询只运行一次 ,因此它自然会为每个时间序列返回一个样本。这就是为什么即时查询通常返回即时向量。
但情况并非如此。例如,将node_cpu_usage作为即时查询进行评估,将获得所有服务器的最新记录值:
node_cpu_usage{instance="server1"} 100
node_cpu_usage{instance="server2"} 50这返回了不同服务器当前的CPU使用率。尽管随着时间的推移记录了许多数据点,但查询仅返回每个时间序列的一个样本即最新的一个样本。
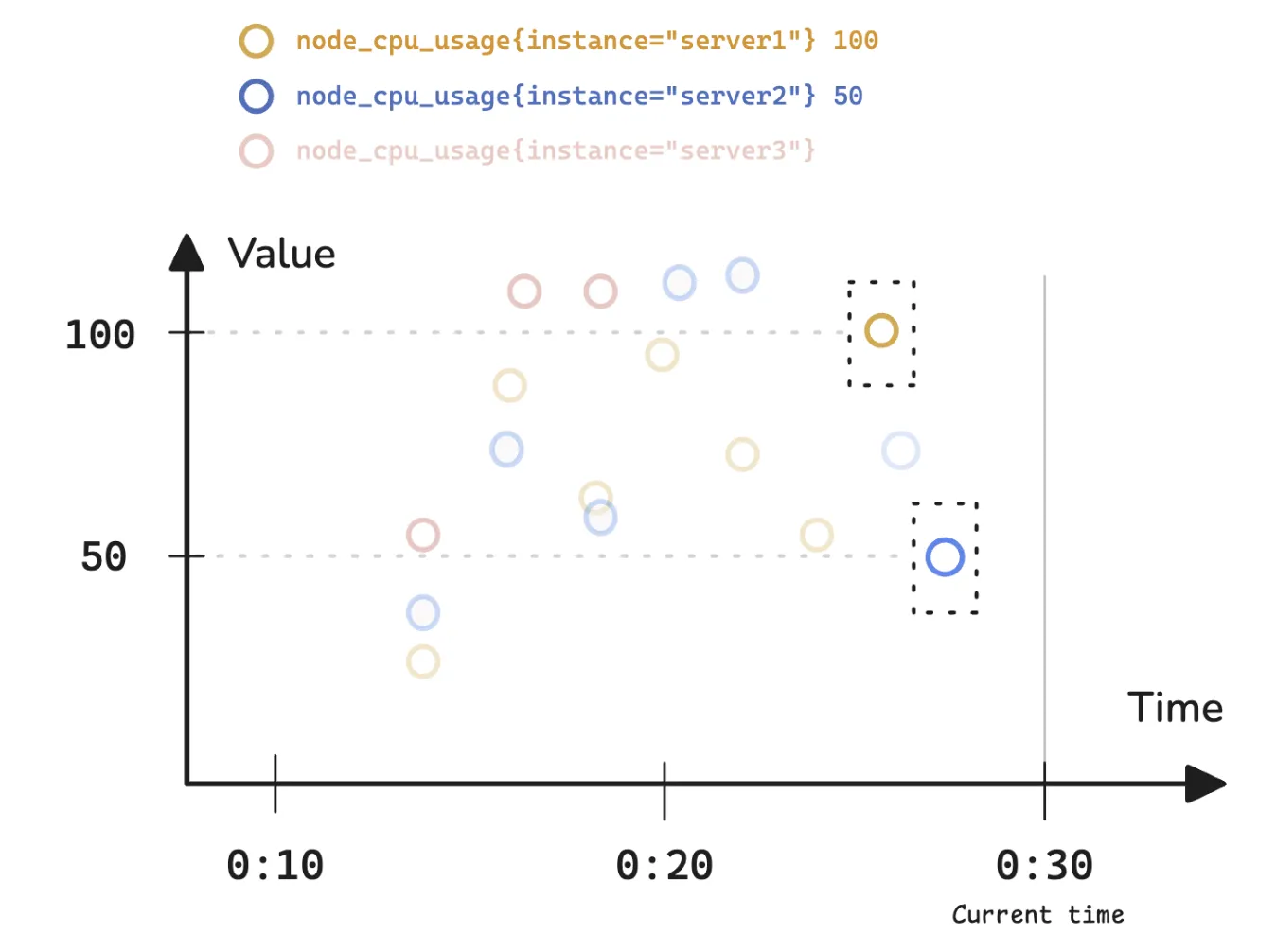
那为什么没有返回node_cpu_usage{instance="server3"}呢?这是因为没有足够新的样本,监控系统并非总能返回每个时间序列的数据。默认情况下,大多数监控工具会回溯5分钟以获取最近的样本,这个时间范围称为回溯增量。
图中的红点表示node_cpu_usageserver3,但它最后一次记录的样本时间距离00:30太远,因此没有出现在结果中。那多远才算远呢?
- 在prometheus中,回溯时间默认为5分钟,可以使用--query.lookback-delta标志更改它
- 在VictoriaMetrics中,没有默认的回溯增量。它会根据样本之间的时间间隔或步长自动决定。也可以使用-search.maxLookback=5m标志来覆盖此设置
也就是说,像node_cpu_usage这样的即时向量选择器在Prometheus中执行时,并不是简单地返回当前时间点的值,而是会在一个默认的回溯窗口(默认5分钟)内查找最近的一个样本。因此,从行为上可以近似理解为last_over_time(node_cpu_usage[5m])。
在VictoriaMetrics中,类似查询会转换为default_rollup(node_cpu_usage[<autogenerated_window>])
其中回溯窗口不是固定值,而是根据数据特征动态计算,从而在稀疏数据场景下获得更稳定的结果。
范围向量
范围向量是一组时间序列,其中每个时间序列包含特定时间范围内的多个样本。它不仅记录最新数值,还能展现指标随时间推移的变化情况。这使得它适用于依赖历史数据的计算,例如平均值、趋势或比率计算。下图显示了一个范围向量:
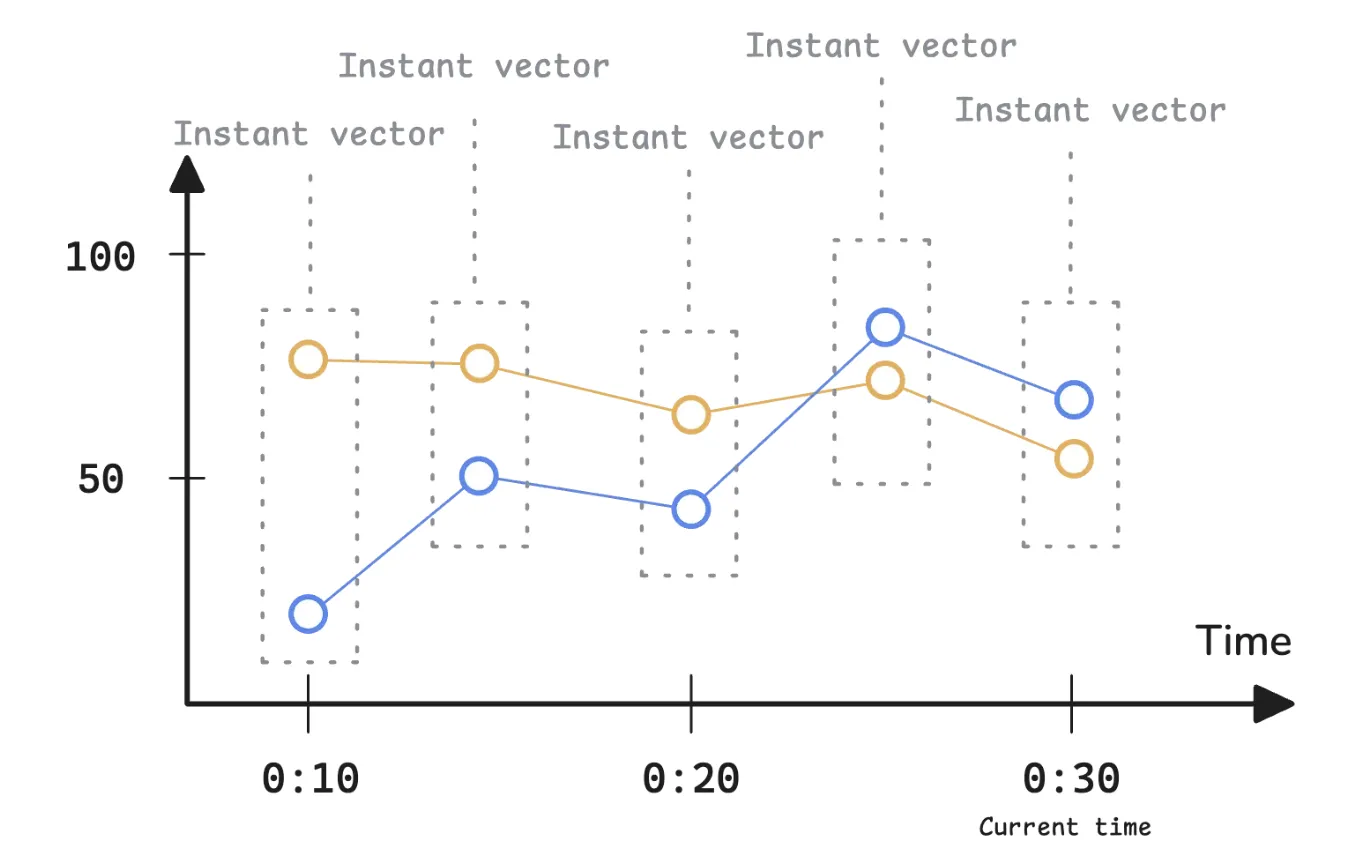
像node_cpu_usage这样的即时向量选择器通常每个时间序列返回一个样本。但是,当作为范围查询进行评估时,它会在时间范围内的多个时间戳进行评估。每次评估都会返回一个即时向量,这意味着范围向量本质上是随时间分布的即时向量的集合。如下,监控系统会在00:10、00:15、00:20、00:25和00:30评估此查询,本质上是每5分钟进行一次快照
node_cpu_usage{instance="server1"} 75 @ 00:10
node_cpu_usage{instance="server1"} 74 @ 00:15
node_cpu_usage{instance="server1"} 65 @ 00:20
node_cpu_usage{instance="server1"} 70 @ 00:25
node_cpu_usage{instance="server1"} 58 @ 00:30
node_cpu_usage{instance="server2"} 22 @ 00:10
node_cpu_usage{instance="server2"} 50 @ 00:15
node_cpu_usage{instance="server2"} 46 @ 00:20
node_cpu_usage{instance="server2"} 81 @ 00:25
node_cpu_usage{instance="server2"} 69 @ 00:30这5分钟的时间间隔称为步长,通常可以在Grafana等查询编辑器中进行配置。大多数情况下,步长会根据所选时间范围自动确定。提交范围查询时,查询编辑器会发送一个带有step参数的请求:
GET | POST /api/v1/query_range?query=...&start=...&end=...&step=...&timeout=...那为什么指标数据是在00:09、00:13和00:16抓取的,结果显示的是00:10、00:15和00:20的数据呢?由于范围查询实际上只是多个即时查询的集合,因此监控系统应用回溯增量来查找每个step的最新样本。
- 00:10:系统评估表达式,回溯5分钟,发现最后一次记录的样本时间为00:09。因此,它将00:10的值记录下来
- 00:15:它再次回溯,发现最后一个记录的样本在00:13。因此,它将该样本记录为00:15
- 00:20:00:20记录的的值来自00:16
时间轴是评估时间,不是采样时间
时间因素
上面已经介绍了回溯增量和步长,但还有一个关键概念需要熟悉,即范围选择器中的窗口。将node_cpu_usage作为即时向量选择器进行评估时,每个时间序列返回一个样本。但添加一个窗口(例如[5m])后,它就变成了一个范围向量选择器 现在,它返回的不再仅仅是最新值,而是该5分钟窗口内记录的所有样本。当使用汇总函数汇总一段时间内的数据时,这尤其有用。例如,要查找过去3分钟(窗口)内每5分钟(步长)的最大CPU使用率,可以使用以下查询:
query: max_over_time(node_cpu_usage[3m])
step: 5m
start: 00:00
end: 00:30系统检索过去3分钟内的所有数据点,以找到这些数据点中的最大值。该过程在整个时间范围内重复进行,每5分钟发出一个新的样本:
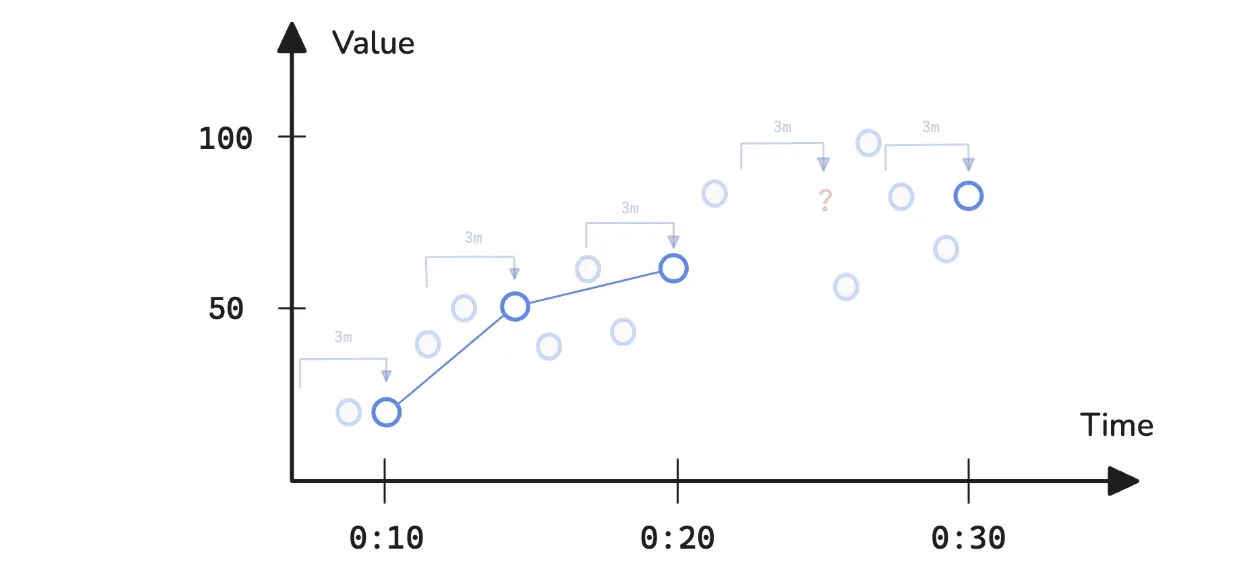
需要注意的是,上图第四个数据点缺失了。这是因为系统会从00:25开始回溯3分钟,但该时间段内没有记录的样本,因此系统无法进行分析。范围选择器也可以通过直接使用[window:step]来定义自己的step。不过,这主要在处理子查询时才有用。
范围向量选择器
范围向量选择器,如http_requests_total[5m]。它被评估为即时查询或范围查询在运行时分别会发生什么情况呢?之前所做的,是将范围选择器放入一个函数中,例如last_over_time(http_requests_total[5m])。再来回顾一下,即时向量选择器会返回一个即时向量。但如果包含范围选择器[window],则每次查询运行时都会返回一个范围向量,或者说每个时间序列会返回多个样本。因此在评估为范围向量选择器时,会引发一些问题:
- 即时查询:没有step参数,表达式只计算一次,但返回多个样本。那么这些样本在时间范围内是如何分布的呢?
- 范围查询:每次评估都返回一个范围向量,而不是单个样本。这在时间序列图表中如何运作?
评估为即时查询
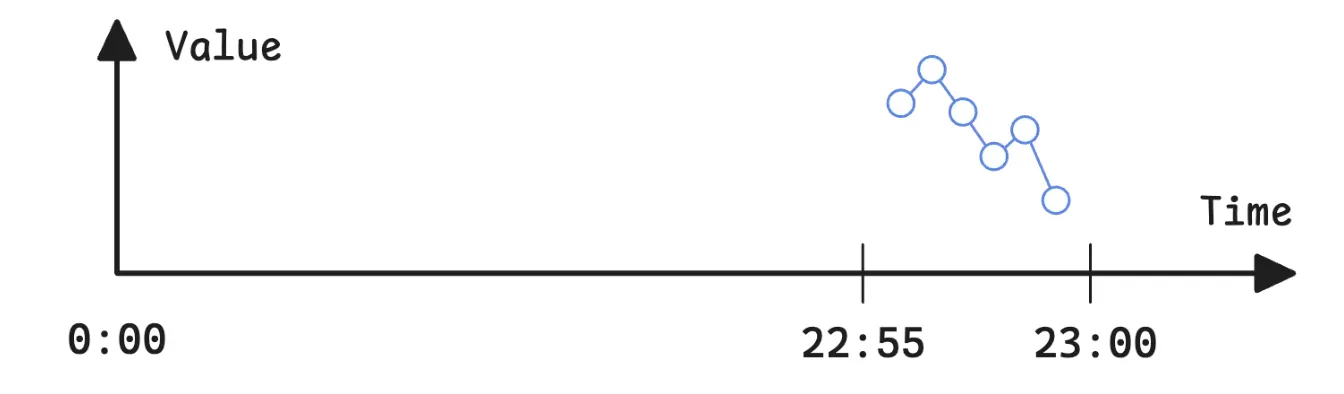 在将http_requests_total[5m]作为即时查询进行评估时,会返回从(T-5m,T)的原始样本。如果在Grafana或任何其他支持即时查询的编辑器中运行此查询,当从00:00到23:00这个时间段中获取数据时,结果可能看起来有点奇怪。它只会包含从22:55到23:00的原始样本。
在将http_requests_total[5m]作为即时查询进行评估时,会返回从(T-5m,T)的原始样本。如果在Grafana或任何其他支持即时查询的编辑器中运行此查询,当从00:00到23:00这个时间段中获取数据时,结果可能看起来有点奇怪。它只会包含从22:55到23:00的原始样本。
所谓原始样本,是指没有应用回溯增量和步长的样本,因此返回的数据点不是均匀分布的。通常情况下,回溯增量会在每个步长间隔内填充缺失的样本。但由于此表达式仅计算一次,因此不存在步长间隔可供使用。结果,系统会直接返回带有原始抓取(或推送)时间戳的数据,与存储时完全相同。
评估为范围查询
在Prometheus中,将http_requests_total[5m]评估为范围查询是行不通的,你会收到以下错误:
query: http_requests_total[5m]
// error:
bad_data: invalid parameter "query": invalid expression type "range vector"
for range query, must be Scalar or instant Vector这是因为Prometheus在执行范围查询时,要求每个评估时间点,每个时间序列只能返回一个样本。但是这个表达式的计算结果是一个范围向量,它会在每个评估时间点,返回每个时间序列的多个样本,这不符合预期的格式(不能用来绘图),因此系统拒绝处理它。所以,根据上面章节中提到的,必须使用函数进行转换:
# 在每个step上,从窗口内取“最新的一个样本”
last_over_time(http_requests_total[5m])