loki
2026年4月6日 · 4057 字 · 更新 2026年4月7日 · 16 阅读
Loki介绍
Loki是一个受Prometheus启发的、水平可扩展、高可用、多租户的日志聚合系统。Loki与Prometheus的不同之处在于,它专注于日志而非指标,并且它是通过push推送而不是pull拉取来收集日志。
Loki只对日志中的标签进行索引,而不对日志全文建立倒排索引。这种“轻量化”的设计使其在存储成本和运维复杂度上远低于传统的 ELK架构。Loki的基本单元是日志流,即共享相同标签的一组日志。因此拥有一组高质量的标签是高效执行查询的关键。并且日志数据会进行压缩并以块的形式存储在对象存储或文件系统中。
除此之外,Loki还支持多租户。并且包含一个ruler的组件,使用它可以评估日志中的异常,并通过Alertmanager实现告警。
架构
Loki采用了基于微服务的架构,所有组件的代码虽然编译在同一个二进制文件中,但通过-target标志,你可以根据集群规模灵活切换部署模式。Loki的架构图如下:
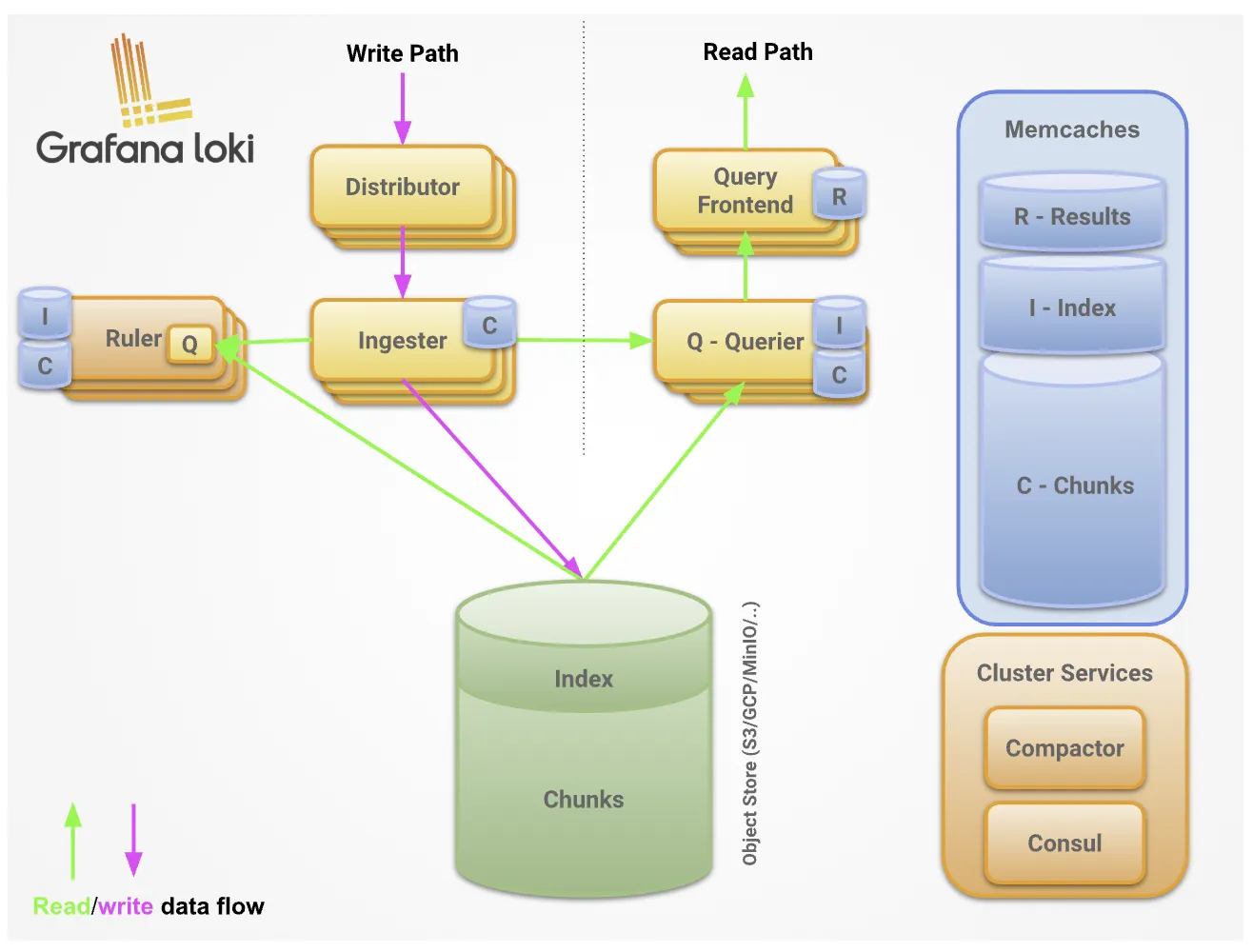
可以看到,Loki包含了多个组件,每个组件的功能如下:
- distributor:分发器,是一个无状态的组件。主要负责处理来自客户端的推送传入请求,是日志数据写入路径的第一步
- 速率限制:可以根据每个租户的最大数据摄入速率限制传入日志的速率
- 复制因子:可以将写入转发到多个Ingester上,防止单点故障。并且为了平衡写入速度和数据安全性,采用了“多数派确认”策略
- ingester:摄取器。负责将数据持久化并发送到写入路径上的长期存储。接收到的每个日志流会先在内存中构建成许多chunk块,再按可配置的时间间隔刷新到后端存储
- WAL预写日志:写入操作会先写入到此处,确保只要磁盘未损坏,数据就不会丢失
- 时间戳排序:loki支持乱序写入。未配置时,Ingester会验证摄入的日志行是否按顺序排列,若收到不符合预期顺序的日志行时,该行将被拒绝,并向用户返回错误
- query frontend:查询前端,是一个可选服务,它提供查询器的API端点,可用于加速读取路径。部署该服务后,传入的查询请求会重定向到该服务而非查询器。查询前端内部执行一些查询调整,然后将查询保存在内部队列中。查询器则充当工作进程,从队列中拉取任务,然后执行,执行的结果会再返回给查询前端进行聚合
- 查询队列:将大型查询拆分成多个小型查询,在下游查询器上并行执行这些小型查询,然后将结果重新拼接起来。防止多个大型请求集中到一个查询器上,遵循FIFO先进先出机制
- 否定缓存:不会缓存该时间范围内具体的日志条目,而是记录下“该时间段内没有任何匹配结果”这一事实。当后续再次发起涵盖该时间段的相同查询时,能够立即识别出哪些时间切片是“空”的,并直接跳过这些数据的读取与处理
- query scheduler:查询调度器,也是一个可选服务,提供比查询前端更高级的队列功能。使用此组件时,查询前端会将拆分后的查询推送至查询调度器,后者会将这些查询放入内部内存队列中。每个租户都有一个队列,以确保所有租户的查询公平性。连接到查询调度器的查询器充当工作进程,从队列中取走作业,然后执行,执行的结果返回到查询前端进行聚合
- querier:查询器,负责执行真正的LogQL查询。它从摄取器和长期存储中获取日志数据。查询器会先查询所有摄取器以获取内存中的数据,如果无法获取,则会回退到后端存储执行相同的查询。由于存在复制因子,查询器可能会收到重复数据。为了解决这个问题,查询器会在内部对具有相同纳秒时间戳、标签集和日志消息的数据进行去重
- index gateway:索引网关,负责处理索引查询。在Loki存储模式下,它能避免每个查询器都去下载巨大的索引文件,显著降低了后端存储的I/O开销
- compactor:压缩器,负责索引的生命周期管理。它不仅能合并细碎的索引文件以优化查询速度,还负责执行数据保留策略,清理超时的过期日志。在loki部署架构中,压缩器通常作为单个实例运行
- ruler:负责管理和评估日志相关的规则,包括记录规则和告警规则。规则配置可以存储在对象存储中,支持通过API动态管理。也可以将规则文件直接上传到对象存储,由ruler自动加载并执行。此外,ruler还可以将规则评估委托给查询前端,这种模式称为远程规则评估,用于利用查询前端的查询拆分、查询分片和缓存等优势。当运行多个ruler时,它们会使用一致的哈希环将规则组分发到可用的ruler实例中
布隆过滤器组件仍处于试验性阶段,是用来提高查询效率的,这里就不做详细介绍了
部署模式
Loki的所有组件都存在于同一个二进制文件中。但可以使用-target命令行标志配置单个二进制文件的行为,以指定启动时要运行的具体组件。并且在配置中,每个组件可以进行单独配置。由于Loki将其存储的数据于摄取和查询数据的软件解耦,因此可以根据需求的变化轻松的以不同的模式重新部署:
- 单体模式:最简单的部署模式,可以通过设置命令行参数
-target=all来启用此模式,会将loki的所有微服务组件运行在单个进程中。该模式适用于每天最多20GB左右的小型读/写量 - 简单可拓展模式:简称SSD,该模式将执行路径分为读、写和后端等多个target。这些target可以独立拓展,让你能够定制Loki的部署架构以满足业务需求。该模式可以拓展到每天几TB的日志量,如果超过这个量,建议使用微服务模式
- 微服务模式:将Loki的每个组件都作为不同的进程运行。维护较复杂
存储
Loki存储的内容分为两部分:
- 索引:存储的是标签与对应的Chunk ID的映射关系,用于高效查询。索引格式为TSDB(BoltDB已经弃用)
- chunk:存储的是多条共享相同标签集的原始日志条目,且经过了高度压缩(通常使用Gzip或Snappy)
在Loki 2.0之前,运维一套Loki往往需要两套存储(例如:用Cassandra存索引,用S3存Chunk),这增加了系统的复杂性和维护成本。而Index Shipper的出现改变了这一切,它是一个巧妙的适配器,可以让Loki能够像处理普通文件一样处理索引,只需要维护一个S3或OSS桶,其工作机制如下:
- 摄取器在本地生成索引文件(通常是BoltDB或TSDB格式)
- Index Shipper定期将这些本地索引文件“运送(Ship)”到远程对象存储中
- 查询器和索引网关则负责从对象存储下载并同步这些索引,以供查询使用
为什么Loki没有使用ES那种全文倒排索引呢?这是因为传统ES会为每个字段都维护一个巨大的词典和倒排列表,会导致索引膨胀。对于高基数、内容高度离散的日志数据来说,这会导致索引体积远大于原始日志数据,从而带来高昂的存储和写入成本。
那为什么ES不这样设计呢?如果ES改成chunk级索引,它就无法实现亚秒级的“精确分页检索”和“复杂的聚合运算”,这对很多搜索业务(如电商搜索)是致命的,所以ES的倒排索引需要行级的。
Loki支持本地磁盘存储和对象存储(在云上更便宜)
数据写入路径
Loki的写入是一个典型的分布式“分发-聚合-刷盘”过程:
- 数据推送:采集端(如Promtail)将带有标签的日志推送到Distributor
- 分发与限流:Distributor检查标签合法性并根据配置进行限流。通过一致性哈希环计算该日志流所属的Ingester,并根据复制因子,将数据并行发送给多个Ingester(通常为3个)
- 写入确认:Distributor 等待多数派(如2个)回复成功后,向客户端返回写入成功
- Ingester内存缓存:Ingester将日志存入内存中的Chunk,同时写入WAL到本地磁盘,防止进程崩溃导致内存数据丢失。且在构建Chunk时,会同步在内存中维护一份反向索引
- 异步推送:当Chunk达到大小(1.5MB)或存活时间达到阈值时,Ingester将其压缩并推送到对象存储。通过Index Shipper适配器,内存索引也会定期推送到对象存储
这里关键的是要了解TSDB原理,后面再做介绍
数据保留策略
在日志系统中,数据不会永久保存。Loki根据你选择的存储后端,采用了两套截然不同的清理策略:
- 本地文件系统:当使用本地磁盘或挂载的卷时,Loki内部的Compactor组件会定期扫描磁盘,它会比对每个Chunk文件的元数据,一旦发现其存活时间超过了全局配置的
retention_period,就会直接执行系统调用将其从物理磁盘上彻底删除 - 对象存储:当数据托管在S3、OSS或GCS时,Loki本身不主动发送DELETE请求给对象存储(为了减少API调用开销和权限风险)。通常需要我们在云控制台或通过IaC在存储桶上配置生命周期规则
核心概念
日志流
在Loki中,日志并不是逐条单独索引的,而是通过标签进行组织和分组,形成所谓的日志流。日志流是由一组具有相同标签集合的日志消息组成的序列。标签是键值对,例如:
{app="nginx", instance="server1"} → 一个日志流
{app="nginx", instance="server2"} → 另一个日志流具有相同标签集合的日志会构建为同一个日志流。另外,每一个日志流都会独立构建和维护自己的chunk,日志文件拆分的流越多,那内存中驻留的chunk就越多,这会导致内存占用增加。而且这些chunk在填满之前就有可能被刷新到磁盘或对象存储了,这会造成空间浪费,压缩效率降低。对应的,索引数量也会增加。
因此,许多小的、未填满的chunk会对Loki产生负面影响。标签策略直接决定了查询性能和系统成本。
标签基数
基数指的是唯一标签和值的组合,它影响你创建的日志流数量。高基数标签会导致Loki构建庞大的索引,并将成千上万的小块刷新到对象存储。当你的标签具有高基数时,Loki的性能会非常差。如果不加以考虑,高基数将显著降低Loki的性能和成本效益。
高基数可能是由于使用了具有无界或大量可能值的标签(例如timestamp或ip_address),或者即使标签具有少量有限的值,也应用了过多的标签。我们要优先使用较少的、具有有限值的标签。标签策略的最佳实践:
- 尽量使用静态标签
- 谨慎使用动态标签:
- 确保标签基数较低,理想情况下限制在数十个值以内
- 使用具有长寿命值的标签,例如HTTP路径的初始部分,如/load, /save, /update等。不要将像trace ID或order ID这样的临时值提取为标签,这些值应该是静态的,而不是动态的
- 只添加用户会频繁用于查询的标签。如果没人使用这些标签,你应该进行清理
- 确保标签值始终是有限的:应该尝试将Loki中的任何单个租户保持在少于10万个活动流,并在24小时内少于一百万个流。这些值是针对每天发送超过10TB的超大型租户而言。如果你的租户大小是其十分之一,则标签数量应至少减少十倍
- 注意客户端应用的动态标签:loki有很多中客户端选项,如grafana alloy、promtail、fluentd、fluentbit、docker插件等。每个客户端都提供了配置应用于创建日志流的标签的方式。但要注意它们生成的动态标签。你可以使用loki的series API查看日志流,也可以使用logcli命令行工具调试高基数标签
乱序摄取
自Loki诞生之初,日志条目必须按时间顺序写入Loki。现在,这一限制已被解除。默认情况下,会全局启用乱序写入,但也可以针对集群或租户单独启用/禁用此功能
- 禁用所有租户的乱序写入
limits_config:
unordered_writes: false- 禁用特定租户的乱序写入
runtime_config:
file: overrides.yaml
# overrides.yaml内容
overrides:
"tenantA":
unordered_writes: falseLoki通过max_chunk_age来控制可接受的乱序日志范围,并基于最新日志时间动态计算一个滑动窗口,从而在保证写入顺序性的同时兼顾系统性能与数据完整性。max_chunk_age的默认值为2小时。Loki会基于以下公式来计算乱序日志最早可以被接受的时间:
time_of_most_recent_line - (max_chunk_age/2) # 默认1h例如,如果max_chunk_age为2小时,并且流bar在8:00有一条日志,则Loki将接受该流的时间范围是07:00 ~ 08:00
结构化元数据
结构化元数据是一种将元数据附加到日志的方式,而无需对其进行索引或将其包含在日志行内容本身中。有用的元数据示例包括Kubernetes Pod名称、进程ID或任何其他经常在查询中使用但基数较高且在查询时提取成本高昂的标签。
为了解决日志JSON解析和高基数标签问题引入的一种机制。它允许在日志中存储结构化字段,例如user_id、trace_id等,但不会像label一样建立索引,从而避免高基数索引问题。在查询时可以直接使用这些字段进行过滤,而不需要每次解析JSON,提高了查询效率。
{service="api"} | metadata status=500 # status就是元数据采集器
Loki原生支持的采集器是Promtail(2026年3月已停止维护)和Alloy。除此之外,还有第三方的采集器也可以使用,例如:Fluentd、FluentBit、Filebeat等。
Alloy后面会详细介绍