kubernetes基础指南(一)
2026年4月6日 · 8308 字 · 更新 2026年4月7日 · 24 阅读
kubernetes介绍
在容器概念出现之后,"如何管理成千上万的容器"成了一个严峻的问题。而Kubernetes应运而生,它最初由Google工程师基于Borg的经验设计。目前已经成为当今最主流的容器编排系统,是云原生生态的事实标准。
kubernetes架构
kubernetes由控制平面和一组运行容器化应用程序的工作节点组成。工作节点承载着应用程序工作负载的Pod,而控制平面用于管理工作节点和Pod。为了提高容错性和高可用性,控制平面通常运行在多台机器上,而工作节点也有多个。kubernetes的架构如下所示:
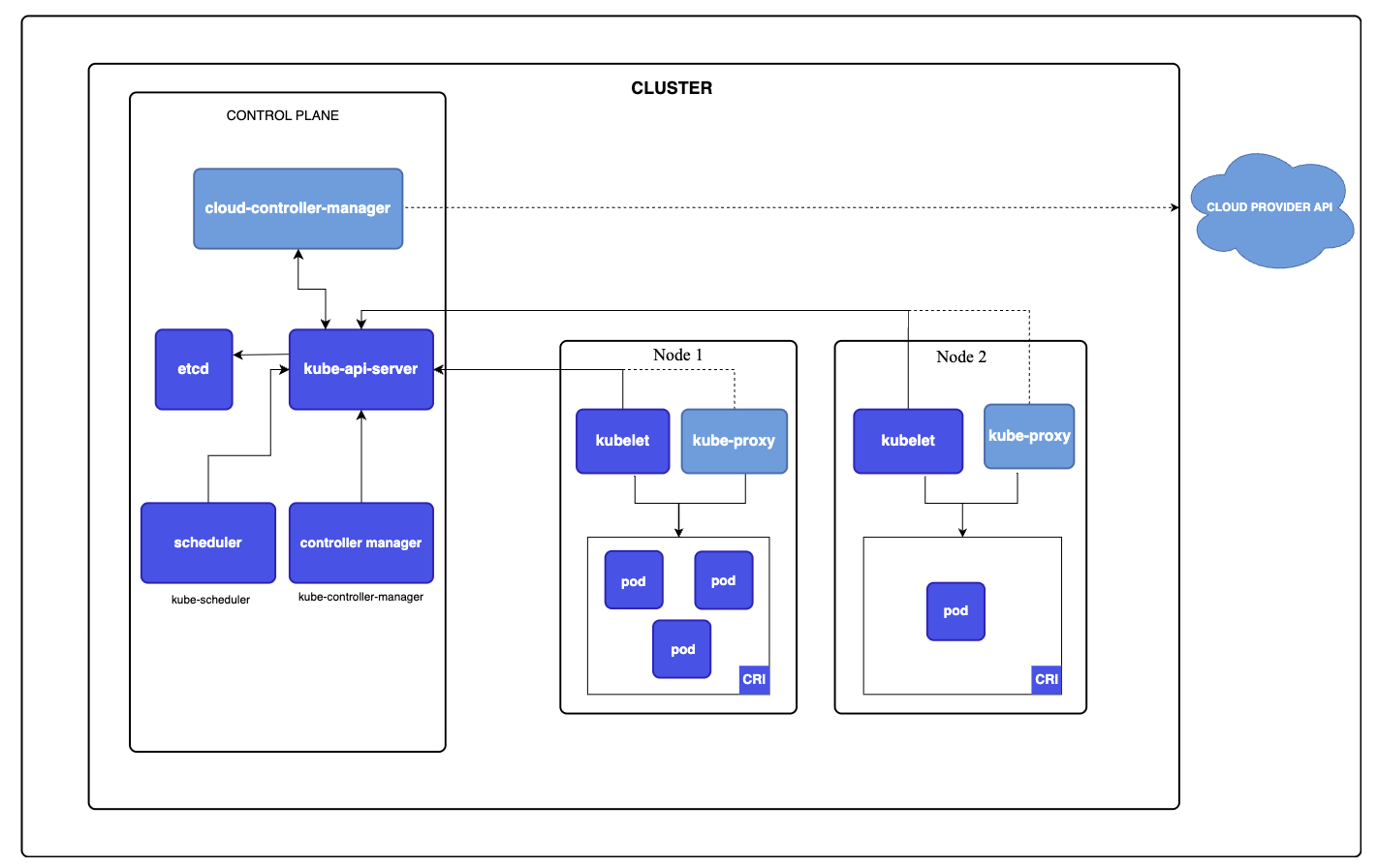
可以看到,kubernetes集群组件分为了两大类:
- 控制平面组件:集群的“大脑”,负责全局决策(如调度)以及探测和响应集群事件
- kube-apiserver:集群的唯一入口。所有组件(包括内部和外部)都必须通过它进行通信。它负责请求的认证、授权及校验
- etcd:一个高可用的键值数据库,存储了k8s的所有配置数据和状态信息
- kube-scheduler:调度器。负责监视新创建的、未指定运行节点的Pod,并根据资源需求、约束条件等逻辑,为它们选择最合适的节点
- kube-controller-manager:运行着多个控制器,会不断循环比对“期望状态”与“实际状态”,如果不一致则进行自动修复
- 数据平面组件:集群的“躯干”,也叫节点组件,在每个节点上运行,负责维护运行中的Pod并提供运行时环境
- kub-proxy:负责实现k8s的Service机制。它维护节点上的网络规则(如iptables或ipvs),使得集群内部或外部的流量能正确转发到Pod
- kubelet:运行在集群的每个节点上,确保容器都运行在Pod中。它不负责创建容器,而是通过CRI指令要求容器运行时去干活
- 容器运行时:实际干活的底层软件。负责运行容器。常见的有containerd和cri-o
Pod
Pod是k8s中可以创建和管理的最小工作单元,由一个或多个容器组成。同一Pod内的容器共享namespace和cgroup资源,也可以通过上下文来进行更进一步的隔离。k8s集群中的Pod主要有两种用途:
- 每个Pod运行一个容器。此时可以将Pod视为单个容器的包装器
- Pod运行多个需要协同工作的容器。多个紧密耦合且需要共享资源的容器构成一个统一的整体
init容器
init容器也叫做初始化容器,该类容器会在应用容器启动之前运行。init容器和常规容器的区别在于某些功能和字段它不支持:
- 不支持资源限制、卷和安全上下文设置
- 不支持lifecycle容器回调
- 不支持livenessProbe、readinessProbe、startupProbe探针检查
- 不支持容器级别的重启策略
由于init容器必须在主容器启动之前成功退出,所以不能为它单独配置重启策略,不然它会陷入无限重启,导致应用容器永远无法启动。另外,如果Pod级别的restartPolicy配置为Never,那init容器失败时,Pod也将会直接标记为失败。
Pod如果发生重启,那init容器也会重新执行,所以它的代码逻辑应该是幂等的
要为Pod指定初始化容器,在Pod配置中添加initContainers字段即可。如下所示
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]sidecar容器
sidecar容器一般作为辅助容器使用,这些容器用于增强或拓展主容器的功能(如日志记录、监控或数据同步等),而无需在主容器中实现。
sidecar容器也可以看作是一个特殊的init容器。虽然它也通过initContainers来定义,但自k8s 1.29版本开始,原本init容器不支持的字段和功能(如restartPolicy),也都集成进来了。这意味着作为特殊init容器启动的sidecar容器,其生命周期独立出来了,它们可以自行启动、停止或重启,而不会影响主容器和其他init容器。
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: alpine:latest
command: ['sh', '-c', 'while true; do echo "logging" >> /opt/logs.txt; sleep 1; done']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail -F /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
volumes:
- name: data
emptyDir: {}另外,sidecar容器不需要优雅停止。只需在其它容器优雅停止之前向sidecar容器发送SIGTERM和SIGKILL信号即可,因此,sidecar容器的退出代码可以不为0(0表示成功终止),这也是正常的,通常应被外部工具忽略。
ephemeral容器
ephemeral容器是一种特殊类型的容器,可见其称为临时容器。它会在现有Pod中临时运行,主要用于故障排查。
临时容器与其它容器的不同之处在于,该类容器不能进行资源限制,也不会自动重启,许多字段和功能也不允许使用。而且它是通过特定的API创建的,因此无法使用kubectl edit命令来添加临时容器。临时容器的创建方式如下:
kubectl debug -it ephemeral-demo --image=busybox:1.28 --target=pod-demo相当于直接在pod-demo这个原有的Pod中,插入了一个新容器。
Pause容器
在Linux中,容器的本质是进程,而隔离靠的是namespace。如果一个Pod里的多个容器要共享网络、PID等,必须有一个共同的引用对象。而Pause容器则扮演了“namespace持有者”的角色,当Pod启动时,Kubelet第一个启动的永远是Pause容器,它启动后会申请一个Network Namespace,随后启动的应用容器(主容器、sidecar、init容器)都会通过container_share_mode加入到Pause容器的namespace中。
它的代码极其简单,核心逻辑只有两件事:
- 无限暂停:调用pause()系统调用,让进程进入睡眠状态,直到接收到信号。它几乎不占用CPU和内存资源
- 接管“僵尸进程”:作为Pod的PID 1进程。当应用容器中的子进程因为各种原因变成孤儿进程时,Pause容器会负责回收它们,防止Pod所在的节点因为僵尸进程过多而崩溃
静态Pod
静态Pod在指定的节点上由kubelet守护进程直接管理,不需要API Server监管,也不经过准入控制器。与控制面管理的Pod不同,静态Pod始终都会绑定到特定节点的kubelet上。
那节点上运行的静态Pod怎么对API Server可见呢?kubelet会通过API Server为每个Pod自动创建一个镜像Pod,只是该Pod不能通过API Server来控制。
静态Pod的创建方式比较独特,它的配置必须放在kubelet指定的目录下(staticPodPath配置),默认是节点的/etc/kubernetes/manifests目录:
cat <<EOF >/etc/kubernetes/manifests/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF创建上面的yaml后,kubelet会自动根据配置启动Pod。而且该Pod不能被kubectl delete命令删除。静态Pod的名称一般为:
- Pod名称 = YAML文件名 - 节点主机名
静态Pod不能引用其他对象,如Secret和ConfigMap等,也不支持临时容器
Service
Service是一种“网络即服务的”机制。k8s会为每个Pod分配独立的IP地址和唯一的DNS名称,并能对它们进行负载均衡。
在k8s中,Pod的IP是会随重启而改变的,为了让服务访问保持稳定,k8s引入了Service。例如,当你创建一个名为order-service的Service时,k8s会在集群内部DNS(CoreDNS)里注册这个名字。流量访问order-service时,k8s底层的kube-proxy会通过控制数据平面的规则(iptables或ipvs),将流量均匀地分发给后端的一组Pod。
Service定义
Service定义配置如下所示:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376以上,创建了一个名为my-service的Service对象,该对象会指向所有带有特定标签的Pod上的TCP端口9376。
k8s会为该Service分配一个IP地址(Cluster IP),该地址由kube-proxy使用。Service控制器会不断搜索与其选择器匹配的Pod,然后向API Server发起一个POST请求,对与该Service对应的EndpointSlices对象中的Pod列表进行必要的更新。
目前,Service支持的端口协议有:TCP、UDP、SCTP。
如果Service中没有selector选择器,相应的Endpoint对象不会自动创建,你需要手动添加
Service类型
在k8s中,Service的类型决定了服务如何暴露给集群内部或外部。目前主要提供了以下4种类型:
- ClusterIP:这是最常用的类型。k8s会在集群内部地址池中分配一个虚拟IP,仅限集群内部
- NodePort:在ClusterIP的基础上,在每个节点上开放一个相同的静态端口。端口的默认范围是30000-32767,集群外部可以通过
<NodeIP>:<NodePort>访问- NodePort冲突避免:端口分配策略适用于自动分配和手动分配两种情况,为了避免两者冲突,端口的默认范围被划分为两个频段。动态端口分配默认使用较高频段,当较高频段用尽后,可能会使用较低频段。用户可以从较低频段分配端口,从而降低端口冲突的风险
- 静态频段:30000-30085
- 动态频段:30086-32767
- 使用特点节点来代理端口:默认情况下,NodePort会在每个节点上都开放对应的端口。但也可以在kube-proxy中使用
--nodeport-addresses配置来定义只有特点的节点才开启代理
- NodePort冲突避免:端口分配策略适用于自动分配和手动分配两种情况,为了避免两者冲突,端口的默认范围被划分为两个频段。动态端口分配默认使用较高频段,当较高频段用尽后,可能会使用较低频段。用户可以从较低频段分配端口,从而降低端口冲突的风险
apiVersion: v1
kind: Service
metadata:
name: test-svc
namespace: default
spec:
type: NodePort
selector:
app: testapp
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
nodePort: 31398- LoadBalancer:在NodePort的基础上,利用云厂商(如阿里云、AWS、GCP)的API创建一个外部负载均衡器。可用于公网或私网全路径访问
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.127- ExternalName:这是一种特殊的类型,它没有选择器,也不转发流量。而是通过DNS映射将服务重定向到外部的域名,用于将集群外部的服务引入到集群内部访问
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.comService流量策略
在Service中,你可以控制k8s的流量策略,来决定k8s如何流量路由到对应的Pod。具体有两种配置:
- spec.internalTrafficPolicy:控制来自内部源的流量如何被路由。即控制集群内部pod访问service的流量策略
- Cluster:默认值,流量可以路由到集群内任意节点上的pod
- Local:仅将流量路由到同一节点上的Pod,如果当前节点没有后端Pod,则可能无法访问
- spec.externalTrafficPolicy:控制来自外部源的流量如何被路由。即控制service外部流量如NodePort、LoadBalancer、ExternalIP的路由策略
- Cluster:默认值,外部流量可以被路由到集群内任意节点上的pod
- Local:仅会将流量路由到本地节点上准备就绪的端点,如果没有本地节点端点,kube-proxy不会转发与相关Service相关的任何流量
此外,Service中的spec.trafficDistribution字段允许你表达对流量如何路由到Service端点的偏好。可以优先将流量发送到与客户端位于同一区域的端点
Headless Service
在某些场景下,你可能并不需要Service提供的负载均衡能力,也不希望分配ClusterIP。这时可以通过将clusterIP设置为None来创建Headless Service。
该类Service没有ClusterIP,kube-proxy也不会对其进行转发或负载均衡处理,集群层面不提供统一的访问入口。由于没有ClusterIP,Headless Service通过集群内部的DNS服务直接返回所有后端Pod的IP地址。客户端可以通过DNS解析拿到Pod列表,自行决定要访问哪个Pod(自己做负载均衡或选择逻辑)。
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
clusterIP: None
selector:
app: my-app
ports:
- port: 80
targetPort: 8080需要注意的是,在Headless Service定义中,如果没有selector选择器,控制平面不会自动创建EndpointSlice,你需要手动创建,这样才能返回DNS解析记录,拿到对应的Pod IP列表。
除此之外,当Headless Service定义中没有selector时,port必须和tartgetPort匹配。
服务发现
对于在集群内部运行的客户端,k8s支持两种Service查找方式:
- 环境变量:Pod启动时,kubelet会根据对应的Service信息往里面注入一组环境变量
{SVCNAME}_SERVICE_HOST{SVCNAME}_SERVICE_PORT
- DNS服务发现:内部DNS服务监听API服务器,根据获取到的Service信息动态生成DNS记录
{SVCNAME}.{NAMESPACE}.svc.cluster.local
环境变量注入方式是静态的,只发生在Pod启动时,而且Service必须先于Pod创建。
DNS服务发现方式是通过API服务器在运行时动态解析的。例如,在命名空间my-ns中有一个名为my-service的Service,那么在集群内部就可以通过my-service.my-ns(或完整域名my-service.my-ns.svc.cluster.local)来解析到对应的ClusterIP。不同命名空间的Pod访问时需要带上namespace,而同一namespace下可以直接使用Service名称。
DNS的能力不仅仅局限于返回IP,还支持SRV记录。如果Service中某个端口被命名为http,并且协议为TCP,那么可以通过_http._tcp.my-service.my-ns这样的SRV查询来获取该服务对应的IP和端口信息。这种方式特别适用于需要动态发现端口的场景,比如gRPC或服务注册发现系统。
此外,对于类型为ExternalName的Service。它也没有ClusterIP,甚至没有Pod后端,而是直接通过DNS返回一个CNAME记录,将Service名称映射到外部域名。例如,可以将my-service映射到my.database.example.com,此时访问该Service实际上等价于访问外部DNS地址,因此ExternalName的唯一访问方式就是DNS,而不会经过kube-proxy或任何集群内部转发逻辑。
会话亲和性
在k8s中,Service还支持一种叫做Session Affinity(会话亲和性)的能力,用来解决“同一个客户端请求是否需要固定访问同一个Pod”的问题。
默认情况下,Service的负载均衡是无状态的,每一次请求都会在后端Pod之间重新分配。但在某些场景下,例如需要维持本地会话状态的应用,可以在Service定义中将sessionAffinity字段设置为ClientIP,让k8s基于客户端IP来进行“粘性路由”,从而尽可能保证来自同一个客户端的请求始终被转发到同一个Pod。
此外,还可以通过sessionAffinityConfig.clientIP.timeoutSeconds来设置超时时间,用来控制这种“粘性连接”的持续时间。默认情况下,这个时间是10800秒,也就是3小时。一旦超过这个时间,k8s会重新进行负载均衡选择,客户端的请求可能会被分配到不同的Pod上。
需要注意的是,这种会话亲和性本质上是“尽力而为”的机制,它依赖kube-proxy的连接跟踪能力实现,并不能保证在Pod重建、扩缩容或网络变化时依然严格保持同一Pod
ClusterIP分配方式
在k8s中,Service的ClusterIP并不是一个真正绑定在某个物理机器或Pod上的IP,而是一个由集群控制平面分配出来的“虚拟IP(VIP)”。当Service被创建时,API服务器会从预先配置好的service-cluster-ip-range网段中为其分配一个唯一的IP地址,确保整个集群中不会出现冲突。
为了避免IP冲突,配置中的网段会根据min(max(16, cidrSize / 16), 256)公式分成上下两层。上层地址用于自动分配机制使用,下层地址留给手动分配的场景使用,从而降低人工指定ClusterIP时发生冲突的概率。
位图分配器
在k8s 1.33版本之前,ClusterIP分配机制是通过位图分配器实现的。它存储在etcd中,用一串二进制位表示整个网段范围内的IP地址的占用情况,其中每一位对应一个IP地址。0表示未分配,1表示已分配。当创建Service时,系统会在位图中找到一个可用的0,并将其设置为1,然后再把对应的IP分给Service。而在Service删除时,只需释放IP,并将对应位置重置为0即可。
这种位图方式的优点非常明显,因为它本质上是对内存中连续位的操作,查找和分配都非常快,通常只需要一次线性扫描或位运算即可完成。同时它的空间效率也很高,一个IP只占用1个 bit,非常适合表示固定范围的地址池。但缺点也很明显:
- 单一网段:强依赖单一连续网段,无法灵活拓展到多个网段
- 规模限制:/12位的ipv4地址还能撑住,但ipv6只能支持/108位。而且地址池越大,位图就越不可控
- 可观测性差:用户无法通过API直接看到分配状态,位图是内部实现细节
- 扩展性差:像Gateway APi、Multi-CIDR这些新需求都不容易接入
- 分布式锁和一致性问题:当多个控制器实例同时尝试分配IP时,需要复杂的分布式锁机制来保证位图状态的一致性
IPAddress和ServiceCIDR
因为位图分配器的种种限制,在后续版本中,k8s逐步演进为基于IPAddress/ServiceCIDR等API对象的分配模型,使IP地址从“内部实现细节”逐渐变成“可观测的API资源”,以支持多CIDR、扩展性更强的网络体系以及更灵活的控制器生态。
kube-proxy
在k8s中,每个节点都会运行一个kube-proxy(也可以替代)。它的核心职责是为Service(除了ExternalName类型)实现一种“虚拟IP机制”。
当集群中创建或删除Service或EndpointSlice时,kube-proxy会持续监听API Server的变化,并在每个节点上同步这些信息。随后,它会根据当前的工作模式(iptables、ipvs等),在节点上生成相应的网络规则,把发往Service的ClusterIP:Port流量拦截下来,并转发到后端的某一个Endpoint(通常是Pod,也可能是用户自定义的IP)。这个过程是持续同步的,因此即使Pod动态扩缩容或发生迁移,Service对外的访问入口仍然保持不变。
之所以k8s采用这种“代理转发”的方式,而不是简单依赖DNS做负载均衡(比如返回多个A记录,然后依赖客户端轮询),主要是因为DNS在现实中存在一些不可控的问题:
- 很多DNS实现并不会严格遵守TTL,可能会缓存解析结果很长时间,导致后端变化无法及时生效
- 一些应用只在启动时做一次DNS解析,并长期复用结果,这会导致负载均衡失效
- 即使应用本身支持定期重新解析,低TTL机制也会显著增加DNS查询压力,使系统难以扩展
相比之下,kube-proxy在每个节点上通过内核层规则实现转发逻辑,使得Service IP成为一个稳定的“虚拟入口”。客户端只需要访问这个VIP,而无需感知后端Pod的变化。这种设计背后的核心思想是:后端Pod是可变的,但Service的访问方式必须保持稳定。因此k8s将“服务发现”和“流量转发”解耦,通过DNS负责解析入口(VIP或Pod列表),通过kube-proxy负责实际的数据转发,从而让前端客户端完全不需要维护后端实例集合。
kube-proxy根据配置支持多种模式,下面一一做介绍。
userspace模式
该模式下,客户端请求访问Service时,数据包会先被节点上的iptables规则捕获,并被重定向到kube-proxy在用户空间中监听的一个端口。此时,连接会从内核态“交给”用户态的kube-proxy进程处理,由kube-proxy根据当前Service的endpoints选择一个后端Pod。随后,它再通过内核网络栈将请求转发到对应的Pod IP上。
由于每一个连接都需要经过“内核态->用户态->内核态”的多次上下文切换,这种模式存在明显的性能开销。另一方面,kube-proxy本身承担了实际的代理转发工作,因此在高并发场景下效率较低。
也正因为这些原因,该模式现在已很少使用。在k8s 1.26版本中已将该模式移除。
iptables模式
在这种模式下,kube-proxy使用内核netfilter子系统的iptables API配置数据包转发规则。对于每个端点,kube-proxy都会为其添加iptables规则,这些规则默认情况下会随机选择一个后端Pod。
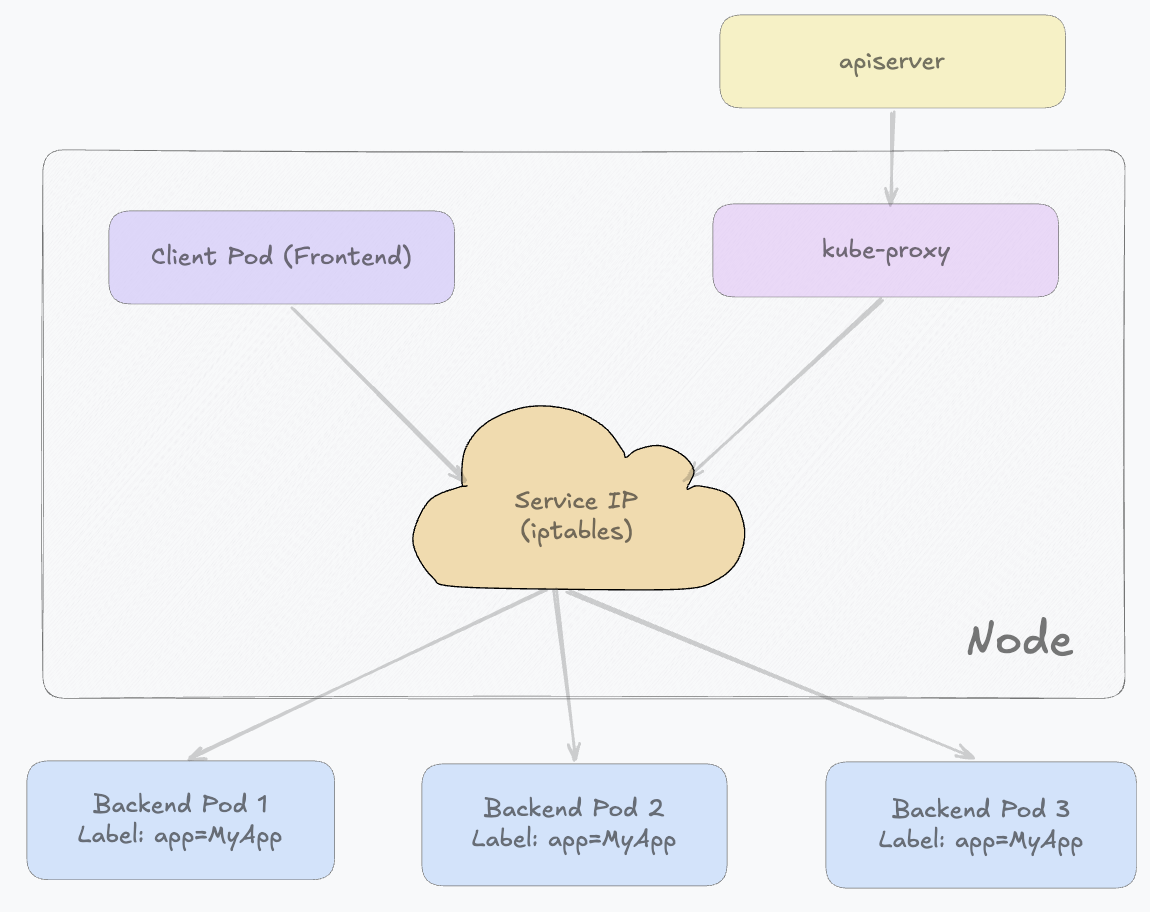
- 客户端请求首先进入Linux内核的网络栈,并经过netfilter的PREROUTING链
- iptables规则识别该请求的目的地址是否是某个Service的ClusterIP
- 如果匹配成功,就会被kube-proxy事先写入的NAT规则拦截,并进行DNAT。原本发往Service VIP的请求,会被直接改写成某一个后端Pod的IP:TargetPort。之后数据包继续在内核中流转,经过路由决策后直接发送到对应的Pod
在这个过程中,kube-proxy本身并不会参与每一次请求的处理,它只负责在Service或EndpointSlice发生变化时,更新节点上的 iptables规则。在负载均衡方式上,iptables模式通常采用概率分发或随机匹配规则来实现“近似轮询”的效果,因此每个连接在建立时会被分配到某一个后端Pod,但一旦连接建立,后续流量会固定走同一个Pod(依赖conntrack)。
整体来看,iptables模式的流量路径完全在内核中完成转发,kube-proxy仅负责规则同步,因此它比userspace模式效率高很多。但在Service和Endpoint规模很大时,iptables规则数量会显著增加,导致同步和匹配成本上升。
需要注意的是,Service与EndpointSlice的变化并不会被实时逐条应用到内核规则上,而是通过一个同步机制批量更新。这其中有两个非常关键的参数:
- minSyncPeriod:控制的是iptables规则同步的最小间隔。当该值设置为0时,每当Service或EndpointSlice发生变化,kube-proxy都会立即触发一次规则同步。这种模式在小规模集群中是可以正常工作的,但在高频变更场景下,会导致大量重复的规则更新操作。而当设置为一个更大的值时,这些频繁的变更会在时间窗口内被“合并”,kube-proxy不再逐条处理每个Pod的变化,而是批量更新规则,比如一次性移除多个Endpoints,从而显著减少CPU开销,提高整体同步效率。但代价是,每个单独的变更可能不会立刻反映到iptables中,而是需要等待一个同步周期结束后才会生效,因此会带来一定的状态延迟
- 通常情况下,如果监控指标
sync_proxy_rules_duration_seconds显示平均同步耗时持续超过1秒,就说明当前同步压力较高,这时适当调大minSyncPeriod可能会让系统更稳定、更高效
- 通常情况下,如果监控指标
- syncPeriod:用于触发一些“定期维护类”的同步操作。例如,当集群中存在外部干预(比如管理员手动修改了iptables规则)时kube-proxy会在syncPeriod到达时重新校正状态。此外,它也用于执行一些周期性的清理任务,以避免历史遗留规则长期累积。在较大的集群中,这个周期通常不需要设置得很小,因为它不会影响正常的流量转发性能。但在过去的某些版本中,将其设置得非常大(例如1小时)曾被用来降低系统开销,不过现在这种做法已经不再推荐,因为它可能导致kube-proxy状态与实际集群状态长时间不一致,从而引发潜在的网络问题
ipvs模式
kube-proxy的ipvs模式可以理解为是在iptables模式之上的一次“内核级升级实现”,它同样运行在Linux节点上,但不再依赖iptables那种逐条规则匹配的方式,而是直接使用Linux内核中的ipvs子系统来完成Service到Pod的流量分发。
在这种模式下,kube-proxy同样会持续监听API Server中Service和EndpointSlice的变化,并把这些变化同步到节点的ipvs规则中,同时还会借助少量iptables规则来完成必要的流量捕获(例如把访问Service ClusterIP的流量导入ipvs处理链)。但核心的负载均衡过程已经不再发生在iptables规则链中,而是交给ipvs在内核态完成。
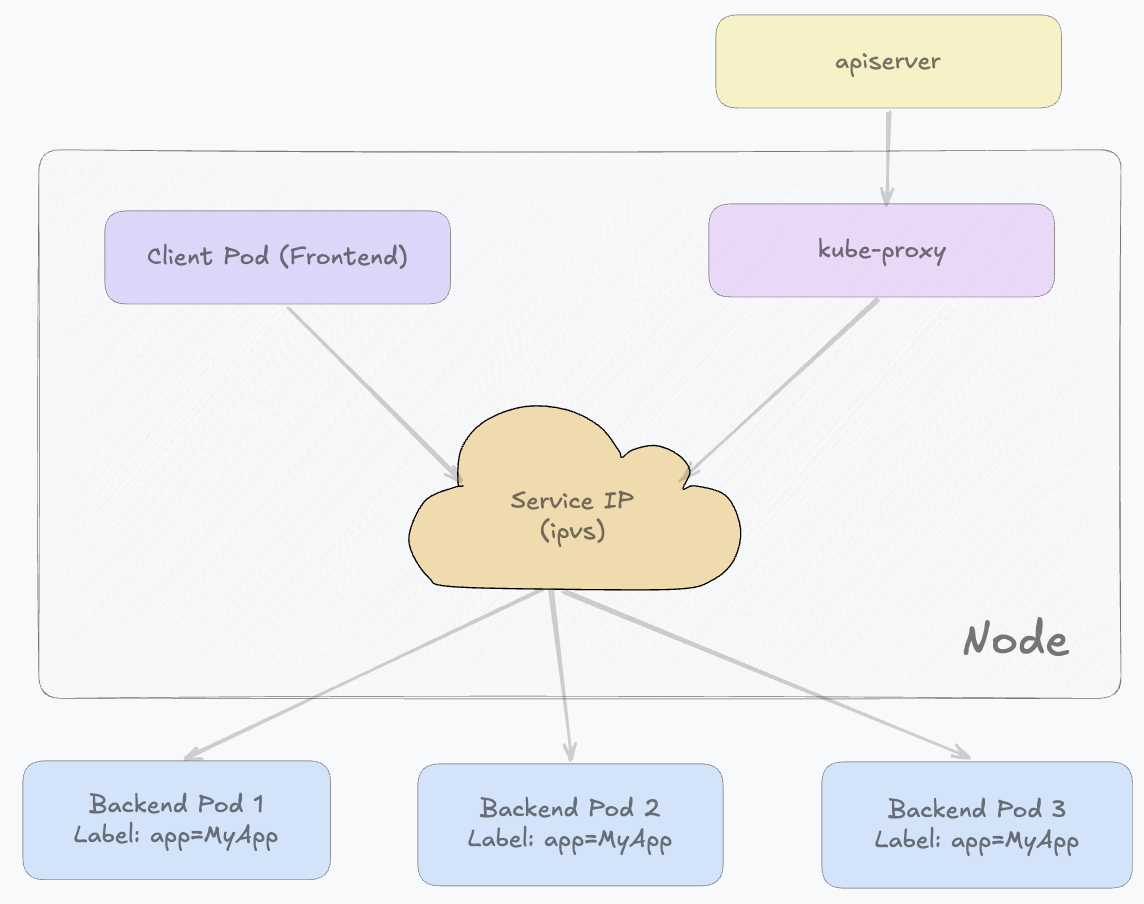
- 客户端请求首先进入Linux内核的网络栈
- 通过iptables做一个“流量引导”,将请求导入ipvs的处理路径
- 进入ipvs后,真正的负载均衡开始发生。ipvs在内核空间维护了一张Service到后端Pod的映射表,这张表底层是基于哈希结构实现的,因此可以非常快速地根据Service VIP查找到对应的后端Pod集合
- 随后ipvs会根据配置的调度算法,从后端Pod中选择一个目标实例
- 选中Pod之后,ipvs会在内核态直接完成DNAT,把原本访问Service VIP的数据包,修改为目标Pod的IP:Port。随后数据包继续在内核中进行路由转发,最终直接发送到目标Pod
ipvs的本质是一个基于哈希表的数据结构,它在内核空间维护Service与后端Pod的映射关系。当请求到达节点并匹配到Service VIP时,ipvs可以通过O(1)级别的查找快速选出一个后端Pod,然后直接将流量转发过去。这种方式相比iptables逐条规则匹配(线性查找)在大规模集群中具有更好的性能和更低的延迟,同时也支持多种负载均衡算法,例如轮询、加权轮询以及最少连接等。
ipvs模式虽然解决了iptables模式在大规模Service场景下规则数量过多、同步开销较大的问题。但随着k8s的演进,ipvs也暴露出一些问题:它的API设计与Service模型并不是完全匹配的,在一些复杂场景(例如特定的流量边界条件、Endpoint变化语义等)上难以做到完全一致的行为,这导致它无法很好覆盖Service的所有边缘用例。
要使用该模式,必须确保节点上的ipvs功能可用
nftables模式
nftables模式是基于Linux内核中更新一代的netfilter框架(nftables)来实现Service转发逻辑的一种更现代化实现方式,本质上是对iptables模式的替代升级。这种模式只在Linux节点上可用,并且通常要求较新的内核版本(例如5.13或更高),因为nftables是Linux内核中更现代的包过滤与规则引擎。
与iptables不同,kube-proxy在nftables模式下不再依赖“链式规则逐条匹配”的方式,而是直接通过nftables API在内核中构建更结构化的规则集合,例如map、set等数据结构。
在运行过程中,kube-proxy仍然持续监听API Server中Service和EndpointSlice的变化。只是它会将这些变化同步到nftables规则中。每个Endpoint通常会对应一条规则或一个集合项,用于描述该Service可以转发到哪些Pod。默认情况下,nftables会在多个后端Pod中随机选择一个作为目标,从而实现负载均衡。
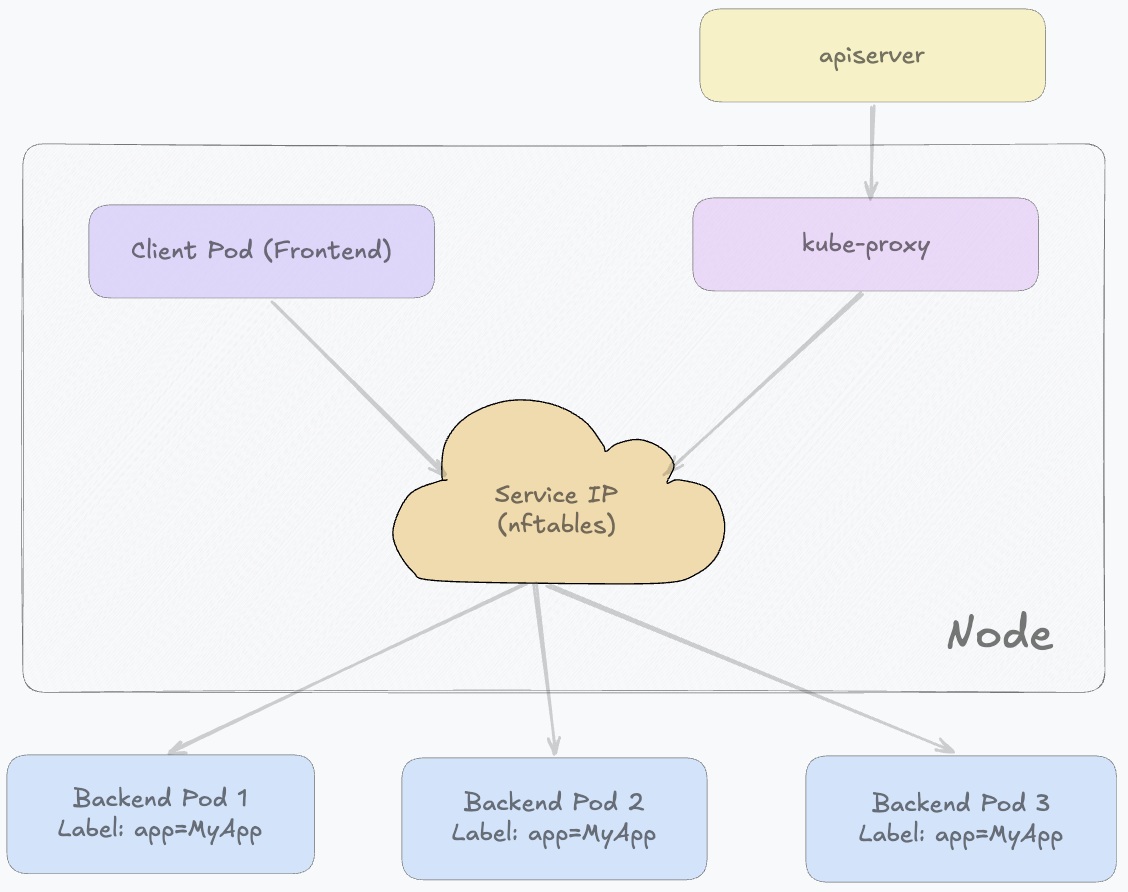
- 客户端请求首先进入Linux内核的网络栈,并在nftables hook点被捕获
- 随后内核根据kube-proxy预先写入的规则直接进行匹配和处理,并在内核态完成负载均衡选择以及DNAT
- 之后数据包继续在内核中转发,最终到达目标Pod
与iptables和ipvs相比,nftables的优势在于它的规则模型更现代、结构更高效,因此在Service和Endpoint数量非常大的集群中,可以显著减少规则同步开销,并提升数据面处理效率。尤其是在大规模集群(成千上万Service)场景下,它能够保持更稳定的性能表现。
不过需要注意的是,nftables模式仍然相对较新(在k8s 1.33左右才逐步进入稳定阶段),因此在某些网络插件或CNI方案中可能尚未完全适配,需要在实际部署前确认兼容性。
iptables和nftables的详细对比可查看:https://www.cnlang.net/blog/iptables
kernelspace
是kube-proxy在windows内核中配置数据包转发规则的模式。此文不多作介绍了,感兴趣的可以去官网查看。
EndpointSlice
在k8s中,Service的后端Pod集合是通过Endpoint体系来维护的,也就是所谓的“端点信息”。早期版本使用的是Endpoints API,但随着集群规模变大,这种设计逐渐暴露出明显的扩展性问题,因此后来被EndpointSlice所替代。
在Endpoints模型中,一个Service只对应一个Endpoints对象,这个对象会集中保存所有后端Pod的IP和端口信息。当Pod数量较少时,这种方式非常直接,但当规模扩大到上千甚至上万个Pod时,这个单一对象会变得非常庞大。每一次Pod的创建、删除或状态变化,都会导致整个Endpoints对象被更新,并推送到API Server和所有节点,这会带来频繁的全量更新和较高的etcd压力。同时kube-proxy或其他控制组件在处理时也必须加载完整列表,导致性能随规模线性下降。此外,原始Endpoints结构也不支持双栈、拓扑信息等更复杂的调度能力,因此逐渐难以满足现代集群的需求。
为了解决这些问题,k8s引入了EndpointSlice作为替代方案。它的核心思想是将“单一大对象”拆分为“多个小切片”。默认情况下,每个EndpointSlice最多包含100个端点,这样一个大型Service的后端Pod会被分散到多个Slice中存储,从而避免单个对象过大带来的问题。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-slice
namespace: default
labels:
kubernetes.io/service-name: my-service # 指定链接的service
addressType: IPv4 # 地址类型
ports:
- name: http
protocol: TCP
port: 80
endpoints: # 不超过100个端点
- addresses:
- 10.0.0.10
conditions:
ready: true
serving: true
terminating: false
topology:
kubernetes.io/hostname: node1
topology.kubernetes.io/zone: zoneA
- addresses:
- 10.0.0.11
conditions:
ready: true
serving: true
terminating: false
topology:
kubernetes.io/hostname: node2
topology.kubernetes.io/zone: zoneA这种分片结构带来的最大优势是增量更新能力。当Pod发生变化时,只需要更新受影响的那一部分EndpointSlice,而不需要重新写入整个端点集合。这大幅降低了API Server和etcd的压力,也减少了kube-proxy在节点侧的同步成本,使系统能够更好地支持大规模集群。
100个端点限制可以通过修改kube-controller-manager的
--max-endpoints-per-slice标志进行调整