ElasticSearch系列指南(一)
2026年4月6日 · 4133 字 · 更新 2026年4月7日 · 52 阅读
介绍
Elasticsearch是一个基于Apache Lucene构建的开源、分布式、RESTful风格的搜索和数据分析引擎。传统的关系型数据库(如MySQL)使用的是“正排索引”(比如B+树),逻辑是:通过文档的ID去找文档里的内容。这就像一页一页翻书找特定的词,遇到全文模糊搜索(比如LIKE '%关键字%')就会导致全表扫描,性能极差。
而ES能够实现毫秒级全文检索,依赖的是倒排索引。它的逻辑是反过来的:通过关键字去找包含它的文档ID。这就像是一本书最后的“词汇索引表”。
核心概念
术语
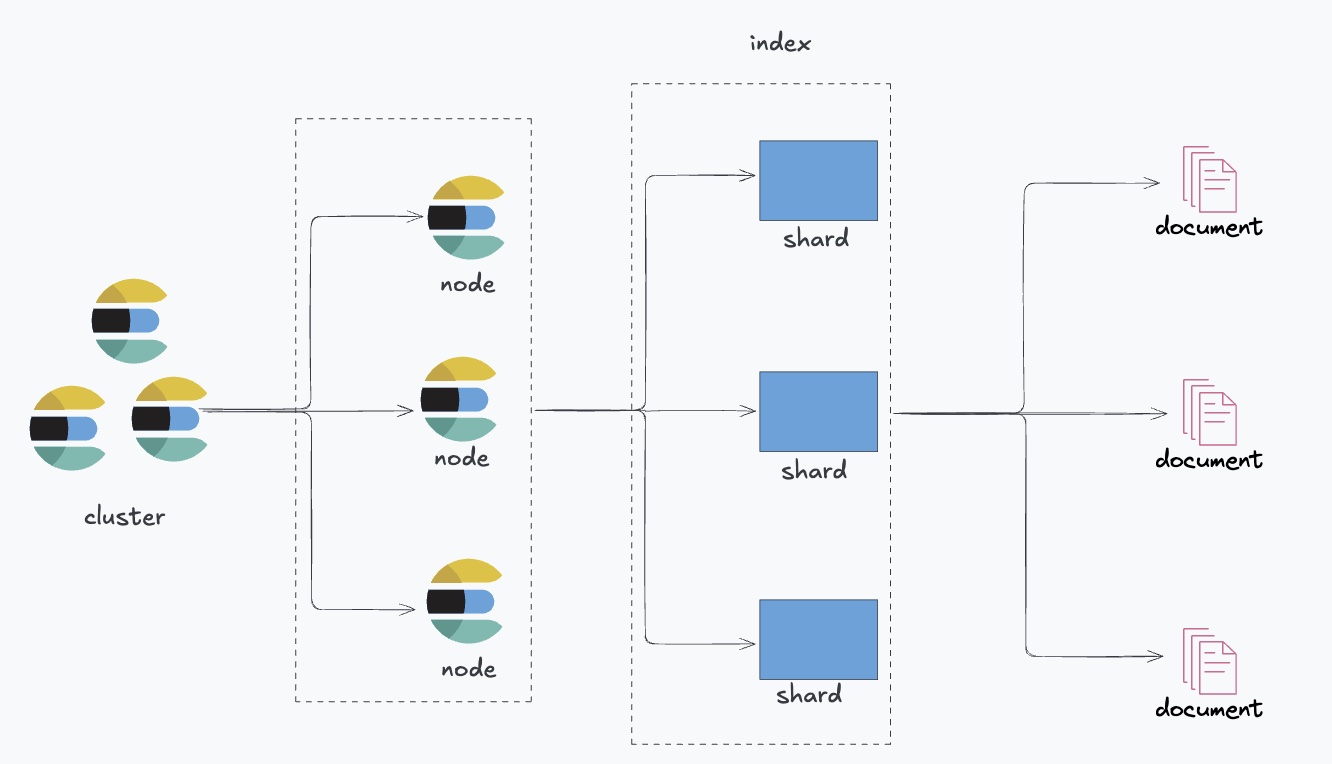
Cluster:集群。是Elasticsearch的基本单位,由一个或多个节点组成,这些节点共同存储数据并处理请求。每个集群都有一个唯一的名称,所有加入该集群的节点都必须配置相同的集群名。集群提供了数据分布、高可用性、负载均衡和故障恢复等功能。ES会自动把索引拆分为多个分片,并分布到不同节点上,因此能够高效处理大规模数据和查询请求。
Node:节点。是集群中的一个ES实例,通常可以理解为一台服务器上的一个ES进程。根据职责不同,节点可以分为多种类型,如主节点、数据节点、协调节点。
Index:索引。是ES中组织数据的基本单位,类似于关系型数据库中的“表”。一个索引包含多个文档,每个索引有唯一名称,用于统一管理同一类数据,可以独立创建、更新和删除。
Document:文档。是ES中最基本的数据存储单元,通常采用JSON格式表示。一个文档就是对某个实体的描述,例如一篇文章、一条日志。
Field:字段。是文档中的一个属性,用于描述文档的具体内容。字段类型决定了数据如何被存储和检索,常见字段类型包括text、keyword、date、boolean等。
Mapping:映射。用于定义索引中字段的结构和类型,类似于关系型数据库中的表结构定义。
Shards:分片。为了提升存储能力和查询性能,ES会将一个索引拆分成多个分片。每个分片本质上都是一个独立的Lucene索引,可以分布在不同节点上。分片通常分为主分片和副本分片。
Replicas:副本。是主分片的复制品,保存与主分片相同的数据。用于提高可用性和查询性能。
Analyzer:分析器。用于处理文本类型字段,将原始字符串转换成适合检索的词项流。通常由字符过滤器、分词器、词项过滤器三部分组成,它们会按照顺序执行。倒排索引中存储的每个词项,都来自分析器最终输出的结果。如果某个词在分析阶段被过滤掉了,那么它就不会进入倒排索引,用户自然也无法通过这个词搜索到对应文档。
分词器
分词器是分析器中最核心的组件,它负责将文本切分为词元(Token),决定了文本检索的基本粒度。常见分词器或内置分析器包括:
- Standard Analyzer:标准分析器,支持基础分词、小写转换等处理
- Whitespace Analyzer:按空格进行切分,适合结构简单的文本
- Custom Analyzer:自定义分析器,用户可以自由组合字符过滤器、分词器和词项过滤器,以满足业务需求
分词器的输出结果会直接影响后续的索引构建和搜索效果,因此在实际项目中需要根据业务场景选择合适的分词方案。对于中文场景,往往还需要额外安装中文分词插件。
倒排索引
倒排索引是Elasticsearch实现高效全文检索的核心数据结构。在传统的“正排索引”中,系统保存的是每个文档有哪些字段,每个字段的具体内容是什么。而在倒排索引中,存储方式反了过来,记录的是:
- 某个词项出现在哪些文档里
- 在这些文档中出现了多少次
- 出现的位置在哪里
倒排索引的核心目标是:通过词项快速定位包含该词项的文档,从而大幅提升全文检索效率。倒排索引通常由两部分组成:
- 词典:词典中保存了所有已经建立索引的词项(Term)。每个词项通常会关联一些元数据,可以把词典理解成“目录”。例如该词项出现于多少个文档中、对应倒排列表在磁盘中的位置
- 倒排列表:每个词项都会对应一个倒排列表,里面记录了该词项出现在哪些文档中,以及相关附加信息。例如文档ID、词频(TF)、出现位置(Position)
假设有以下三条文档:
- 文档 1:Elasticsearch is fast
- 文档 2:Elasticsearch is scalable
- 文档 3:Search engines are fast经过分析器处理后,可能得到如下结果:
# 词项字典
Term Doc Count
elasticsearch 2
engines 1
fast 2
scalable 1
search 1
# 倒排列表
elasticsearch -> Doc1(Position:0), Doc2(Position:0)
engines -> Doc3(Position:1)
fast -> Doc1(Position:2), Doc3(Position:2)
scalable -> Doc2(Position:2)
search -> Doc3(Position:0)倒排列表中可能还附带文档ID、TF等信息。
另外,需要注意的是,为什么is和are没有出现在倒排索引中?这是因为它们通常会被词项过滤器中的stop filter(停用词过滤器)过滤掉。像the、a、is、are这类词语出现频率很高,但通常对搜索相关性的贡献较低。将它们过滤掉可以节省索引存储空间、提高检索效率。当然,这并不是绝对的。如果业务确实需要,也可以选择保留这些停用词。
构建流程
参考上面的实例,倒排索引的构建一般包括以下几个步骤:
- 文档分词:在文档写入ES之前,文本内容会先经过分析器处理,被切分成多个词项。例如大写转小写、去除无意义字符
- 去除停用词:分析过程中,一些无意义或贡献较低的高频词会被过滤。例如the、a、is
- 构建词典:系统会收集所有词项,并生成词典。词典一般会按一定顺序组织,便于快速查找
- 构建倒排列表:对于每个词项,记录它在哪些文档出现过的文档ID,以及可能的词频、位置等信息
- 存储倒排索引:最终,倒排索引会被写入磁盘,并根据需要加载部分结构到内存中,以支持高效查询
再看一个完整的例子。假设现有三个文档:
- 文档1:The quick brown fox
- 文档2:A quick brown dog
- 文档3:The lazy dog jumped over the quick brown fox文档分词后,会变成
- 文档1:["The", "quick", "brown", "fox"]
- 文档2:["A", "quick", "brown", "dog"]
- 文档3:["The", "lazy", "dog", "jumped", "over", "the", "quick", "brown", "fox"]之后,去除停用词
- 文档1:["quick", "brown", "fox"]
- 文档2:["quick", "brown", "dog"]
- 文档3:["lazy", "dog", "jumped", "quick", "brown", "fox"]然后构建词典
{
"quick": [1, 2, 3],
"brown": [1, 2, 3],
"fox": [1, 3],
"dog": [2, 3],
"lazy": [3],
"jumped": [3]
}再构建倒排列表
quick -> [doc1, doc2, doc3]
brown -> [doc1, doc2, doc3]
fox -> [doc1, doc3]
dog -> [doc2, doc3]
lazy -> [doc3]
jumped -> [doc3]查询流程
当用户搜索quick brown时,ES会先到倒排索引中查找:
- quick对应的文档集合:[doc1, doc2, doc3]
- brown对应的文档集合:[doc1, doc2, doc3]
然后对两个结果求交集,得到:doc1、doc2、doc3。
因此,这三个文档都会被返回。当然,在真实场景中,ES不只是简单返回结果,还会结合词频、相关性评分、字段权重、短语匹配、BM25等算法来决定最终排序。
集群
集群协调机制
ES集群由多个节点组成,在这些节点中会选出一个主节点作为整个集群的“控制面”。在ES 6.x及更早版本中,集群发现与主机点选举主要由Zen Discovery协议负责。但从ES 7.0开始,官方重写了集群协调层,使用新的cluster coordination subsystem来完成。
新的集群协调机制本质上是一个基于多数票投票的一致性系统。它借鉴了分布式一致性算法的思想,但并不是对Paxos或Raft的简单照搬,而是Elastic为自身场景专门实现的一套协调机制。
当一个节点启动后,如果当前还不知道主节点是谁,就会进入discovery流程。其中有两个非常重要的配置参数:
- discovery.seed_hosts:用于节点间互相发现。告诉节点在启动时可以先去联系哪些种子节点
- cluster.initial_master_nodes:只用于一个全新集群第一次启动时的引导选举。改配置中的节点可以作为
master-eligible节点,只有这类节点才能参与选主流程
如果节点都配置了node.name,那cluster.initial_master_nodes配置中应该填写各节点node.name所指定的名称
主节点选举
ES的主节点选举只允许master-eligible node参与。在现代版本中,节点会先进行发现,再结合当前投票配置尝试完成选主。可以把流程概括为以下几步:
- 节点发现:节点会根据discovery.seed_hosts中的地址去探测其他节点,并交换自己已知的master-eligible节点信息。这样每个节点都能逐步获得更完整的候选节点视图
- 发起选举:当节点发现当前没有可用主节点时,会由某个master-eligible节点率先发起选举。现代ES在正式选举前加入了类似PreVote的预投票机制,用于减少网络抖动时无意义的任期增长
- 多数派投票:候选节点会请求其它投票节点支持自己。只有获得超过半数投票后,候选节点才能成为新的主节点。这里的“多数”并不是对全体节点求多数,而是基于当前参与投票的节点求多数
- 发布集群元数据:新主节点当选后,会负责生成并发布新的cluster state。只有在得到多数投票节点确认后,这个cluster state才算正式提交。这也是ES保证集群元数据一致性的关键
故障恢复
集群运行过程中,节点之间会通过心跳持续进行故障检测。如果某些节点连续多次无法确认当前主节点可达,就会认为主节点可能失效,然后重新进入选举流程。故障恢复可以分为两个层面:
- 集群协调层恢复:如果主节点失联,节点会重新发起主节点选举,新主节点产生后,会发布新的cluster state,集群恢复对元数据的统一管理能力
- 分片层恢复:如果故障节点上原本承载了分片,主节点会把失效节点上的分片标记为不可用。若某主分片失效,但仍有可用副本,则会将某个副本提升为新的主分片。然后根据当前健康节点情况,重新补齐副本分片
分片机制
每个索引都会被拆分成多个主分片,每个主分片又可以拥有若干个副本分片。主分片负责接收写入操作,副本分片则保存主分片的数据副本,提升可用性并分担读请求。当主分片所在节点故障时,某个副本分片可以被提升为新的主分片继续服务。
对于现代版本,官方默认是1个主分片 + 一个副本分片。早期版本曾默认5个主分片,后官方改成1个主分片,主要是为了减少过多小分片带来的cluster state膨胀和资源浪费问题。
另外需要注意的是,主分片数量只能在创建索引时指定,后续不能直接修改。而副本数量可以动态调整。
分片路由
当写入一个文档时,该文档会被存放到哪个分片中是由路由机制实现的。
ES的分片路由机制,核心不是一致性哈希算法,而是基于_routing值的哈希计算。默认情况下,文档的_routing值就是_id。因此,同一个文档ID在主分片数不变时,总会稳定地落到同一个主分片上。
目标分片 = hash(document_id) mod num_primary_shards
如果启用自定义路由,则可以把同一业务维度的数据,例如user_id、tenant_id,稳定地路由到同一分片,以减少查询fan-out。它的优点是定位稳定、读取和更新效率高,而且指定routing后,查询只需打到相关分片即可。但也有风险,那就是自定义routing后,读写时必须保持routing一致,而且_id的全局唯一性需要自行保证。
目标分片 = hash(Custom Routing Value) mod num_primary_shards
在ES集群中,一次写入操作的典型流程如下:
- 客户端将请求发送到任意节点,这个节点充当协调节点
- 协调节点根据routing计算目标主分片
- 请求转发到目标主分片所在节点
- 主分片先执行写入,并写入本地Lucene索引缓冲区与Translog
- 主分片再并行把这次操作转发给所有
in-sync replicas - 副本分片执行同样的写入操作
- 当主分片确认所有需要同步的副本都成功后,才向客户端返回成功
由上可知,副本分片并不会主动从主分片拉取新的写入数据,而是执行主分片下发的操作,这会导致主分片承担更大的压力。因此,副本分片数量越多,主分片的网络、CPU与复制开销就越大,甚至可能导致写性能下降。真正提升写吞吐的方式通常是增加主分片的数量,让更多的主分片承担写流量。
wait_for_active_shards配置决定在写入时,至少要多少个分片写入完成才算成功
拓展
Refresh
refresh的作用是让新写入的数据对搜索可见。ES默认会周期性refresh,现代Stack默认通常是1s。也就是说,写入成功并不代表“立刻可搜索”;通常要等下一次refresh,或者显式使用refresh=true / refresh=wait_for。
需要注意的是,refresh不是“刷盘”,而是将indexing buffer写成segment,这些segment很多时候仍然只存在于系统缓存中,因此,“可搜索”并不代表“崩溃安全”。
Translog
Translog才是是ES保证崩溃恢复能力的关键机制,可以将其看作是预写日志(WAL)。由于Lucene commit成本非常高,不可能每次写请求都立刻执行完整commit,因此每次写入除了更新Lucene内部结构外,还会追加写入translog。节点异常崩溃后,ES会在恢复阶段回放最近一次Lucene commit之后的translog,从而尽量减少数据丢失。现代ES默认的配置是:
- index.translog.durability = request
- index.translog.sync_interval = 5s这两个配置很容易被误解。默认并不是“每5秒才刷一次translog”,因为在request模式下,每个index/delete/update/bulk请求返回成功前,主分片和所有已分配副本分片的translog都已经完成fsync,因此默认情况下已确认写入通常不会因为节点崩溃而丢失。只有在:
index.translog.durability = asyncES才会按sync_interval周期性fsync,此时最近几秒内已经ACK的数据在节点异常宕机时可能丢失。另一方面,Flush则会真正触发 Lucene commit,并开启新的translog generation;而Refresh仅解决“搜索可见性”,并不直接提供数据持久性。