聊聊docker
2026年4月6日 · 2730 字 · 更新 2026年4月7日 · 41 阅读
操作系统级虚拟化
现代主流的虚拟化技术有操作系统级虚拟化和硬件辅助级虚拟化。硬件辅助级虚拟化的每个虚拟机都有完整的操作系统,比较重;而操作系统级虚拟化是一种轻量级虚拟化技术,它不需要为每个虚拟实例运行完整的操作系统,而是多个虚拟实例之间共享内核,并通过内核的隔离机制独立运行。
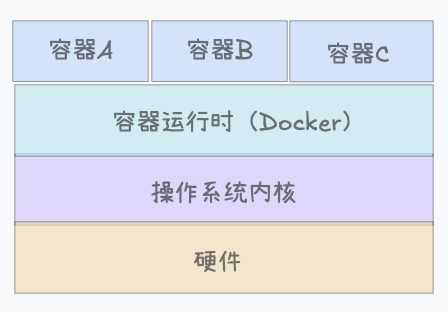
内核的资源隔离机制就是Namespace,它可以让每个虚拟实例“看到”的世界不同。常见的Namespace及其作用:
- PID:进程隔离。不同容器中的进程编号彼此独立,容器内看到的PID从1开始
- NET:网络隔离。每个容器拥有独立的网络栈,包括IP、端口、路由表等
- MNT:文件系统隔离。容器拥有独立的挂载点视图,可以挂载不同的文件系统
- UTS:主机名隔离。每个容器可以拥有独立的hostname
- IPC:进程通信隔离。不同容器之间无法通过共享内存等方式通信
需要注意的是,Namespace并不是完整的隔离机制。由于所有容器共享同一个内核,如果内核存在漏洞,可能会影响所有容器。另外,Namespace通常需要配合cgroups一起使用,实现资源限制。
Cgroups
如果说Namespace能决定容器能“看到什么”,那cgroups则是决定容器“能用多少”,其原理是划分宿主机资源。在Linux中,cgroups的接口以伪文件(pseudo-filesystem,通常称为cgroupfs)的形式呈现。用户空间可以通过读写这些伪文件来配置资源限制或获取运行时统计信息。cgroups目前主要分为v1和v2两个版本
- 在cgroup v1中,不同的资源控制器(controller,如CPU、memory)是彼此独立的,每个controller都有自己单独的层级结构。这种设计虽然灵活,但也带来了一个问题:不同controller的层级可能不一致,从而导致资源管理语义复杂且容易冲突
- 而在cgroup v2中,引入了统一层级(unified hierarchy)的设计:所有controller共享同一棵目录树,资源限制以自上而下的方式继承。这种方式使资源管理更加一致,也更容易理解和维护
通过如下命令可以看到docker所使用的cgroup版本:
$ docker info | grep -i "cgroup version"
Cgroup Version: 1cgroupfs对应的挂载位置通常在/sys/fs/cgroup
$ tree /sys/fs/cgroup/ -L 1
/sys/fs/cgroup/
├── blkio
├── cpu -> cpu,cpuacct
├── cpuacct -> cpu,cpuacct
├── cpu,cpuacct
├── cpuset
├── devices
├── freezer
├── hugetlb
├── memory
├── net_cls -> net_cls,net_prio
├── net_cls,net_prio
├── net_prio -> net_cls,net_prio
├── perf_event
├── pids
└── systemd可以看到,在cgroup v1中,不同的控制器会挂载在不同的子目录下,例如cpu、memory、blkio等。这意味着每个controller都拥有各自独立的层级结构。同一个进程在不同controller下可能属于不同的cgroup,从而导致资源管理在语义上存在一定复杂性
docker
docker是典型的操作系统级虚拟化技术。它采用了分层架构,其核心组件可分为三部分:
- 客户端:Docker Client。是用户与Docker交互的入口,常见的形式就是docker命令行工具
- 服务端:Docker Daemon(dockerd)。负责接收客户端请求、管理镜像和容器、调度底层运行时
- 容器运行时:Container Runtime。负责真正创建容器
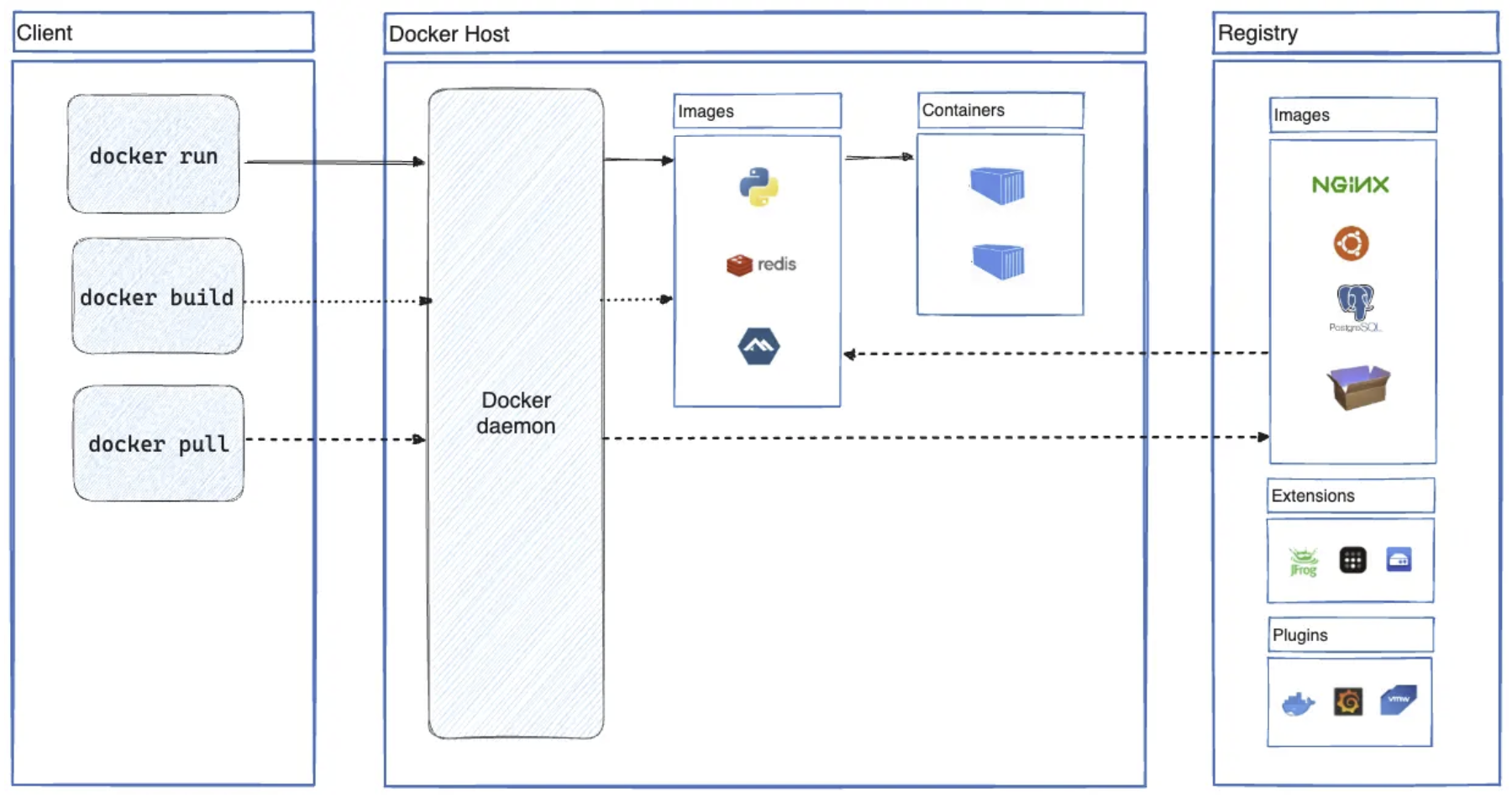
当执行docker run时,Docker的整体流程如下:
- Docker Client发送请求给Docker Daemon
- Daemon拉取镜像(如果本地不存在)
- Daemon调用containerd创建容器
- contained调用runc
- runc调用Linux内核:
- 使用Namespace实现资源隔离
- 使用cgroups实现资源限制
- systemd将容器进程纳入cgroup管理(scope)
cgroup驱动模式
在docker中,cgroups有两种驱动模式:
- systemd模式:在这种模式下,systemd接管了cgroup层级的管理。Docker本身作为一个systemd service(docker.service)运行在system.slice下,而每个容器则被创建为一个独立的scope单元。资源限制与systemd unit生命周期绑定,能够自动回收资源,避免残留cgroup
- cgroupfs模式:在该模式下,Docker直接操作cgroup文件系统(cgroupfs),绕过systemd。这种方式虽然更加“直接”,但也带来一些问题。那就是与systemd的资源管理可能冲突,容器进程可能被systemd重新归类,缺乏统一的生命周期管理
在systemd中,unit是资源管理的基本单位,常见的有三种:
- service:用于管理长期运行的服务进程(例如docker.service)
- slice:用于组织和划分资源层级,本质上对应cgroup的目录结构
- scope部分:用于管理“外部创建”的进程(例如Docker容器)
在默认的systemd模式下,工作流程紧密围绕systemd unit的生命周期展开。当创建一个容器时,systemd就会为其创建一个对应的cgroup路径,例如:
- /sys/fs/cgroup/system.slice/docker.service/docker-container-id.scope/
这个目录就是该容器对应的cgroup控制组,目录下面的文件就是该cgroup的控制接口文件。Docker和systemd通过写入这些文件来实现对容器资源的限制。下面的一些命令可以帮你查看更详细的内容:
# 查看unit属性
systemctl show docker-<container-id>.scope
# 查看systemd树状结构
systemd-cgls镜像
Docker镜像本质上是一个分层的文件系统,由多层只读文件系统叠加而成。这些层通过联合文件系统(UnionFS)进行组合,对外呈现为一个完整的文件系统视图。
镜像由一层一层的文件系统组成,每一层都是只读的。在构建镜像时,Dockerfile中的每一条指令(如RUN、COPY、ADD)都会生成一个新的镜像层。也就是会生成多个只读层,按顺序叠加构成最终镜像。这些只读层在多个容器之间是共享的,从而大大节省了磁盘空间。
在Linux中,Docker默认使用Overlay2作为存储驱动,它基于OverlayFS实现。OverlayFS就是一种联合文件系统,可以将多个目录“叠加”成一个统一的视图,对外表现为一个完整的文件系统。在Overlay2中,一个容器的文件系统由以下几个部分组成:
- lowerdir:只读层(镜像层,可以有多层)
- upperdir:可写层(容器独占)
- workdir:工作目录(内核内部使用)
- merged:最终挂载给容器的目录(统一视图)
可以理解为:merged = lowerdir(多层只读) + upperdir(单层可写)
Overlay2的核心机制是写时复制。当容器尝试修改一个文件时,如果文件存在于只读镜像层(lowerdir),OverlayFS会先将该文件复制到upperdir,然后对upperdir中的副本进行修改。从此之后,该文件的访问将优先命中upperdir中的版本,这种机制既保证了镜像层的只读性,又避免了不必要的数据复制。
在运行时,一个容器的文件系统可以理解为:多个只读镜像层(lowerdir)、一个独立的可写层(upperdir)。多个容器可以共享同一组只读镜像层,但各自拥有独立的可写层,从而实现隔离与高效复用。
从更底层的角度来看,Linux文件系统通常可以分为:
- bootfs(引导文件系统):包含bootloader和内核镜像,用于系统启动。在传统虚拟机中,每个实例都有自己的bootfs。但在容器中,由于共享宿主机内核,因此并不需要独立的bootfs
- rootfs(根文件系统):是容器运行时真正使用的文件系统,包含/bin、/lib、/etc等基础目录,应用程序及其依赖。在Docker中,镜像的分层结构本质上就是用于构建rootfs。
可以总结为:rootfs = 多层只读镜像层 + 一层可写容器层
因此,Docker镜像并不是一个“完整操作系统”,而是一个构建运行环境的文件系统快照,其运行依赖于宿主机内核。
网络
Docker网络本质上是基于Linux网络能力(network namespace、veth pair、bridge、iptables)构建的一套容器通信机制。可以从三个层面理解:
- 网络隔离:通过network namespace实现
- 数据转发:通过veth + bridge实现
- 流量控制:通过iptables实现
当Docker创建一个容器时,会先创建一个network namespace用于实现网络隔离。然后创建一对veth虚拟网卡,一端放入容器(作为eth0),一端留在宿主机。再将宿主机侧的veth接入docker0网桥,为容器分配IP地址,并配置默认路由
docker0位于宿主机的network namespace中,而容器运行在独立的network namespace中,不同namespace之间的网络设备无法直接互通。因此,容器无法直接将自己的网卡“接入”到docker0上,而是需要借助veth(虚拟以太网设备)实现跨namespace的连接。通过这种方式,容器可以“间接”接入docker0,从而实现与宿主机以及其他容器之间的通信。
Docker使用iptables来管理容器的网络访问控制。在默认配置下,Docker会将filter表中的FORWARD链默认策略设置为DROP(防止未授权流量转发),然后创建一系列自定义链来精细控制流量。容器相关流量(如端口映射、容器间通信、访问外网)通常会经过:
FORWARD
→ DOCKER-USER:用户自定义规则(优先级最高)
→ DOCKER-FORWARD:用户自定义规则(优先级最高)
→ DOCKER:端口映射(NAT)
→ DOCKER-INGRESS(Swarm模式):Swarm服务负载均衡Docker通过这些链将“容器网络流量”纳入可控范围,而不是直接依赖系统默认规则。
网络模式
docker主要有六种网络模式:
- bridge:桥接(默认)。容器连接到docker0网桥,容器之间可以通过IP通信,并通过NAT实现访问外网
- host:容器与宿主机共享网络命名空间,不再有独立IP,而是直接使用宿主机端口
- none:容器没有网络,只有loopback(lo)
- container:容器与另一个容器共享网络命名空间
- macvlan:每个容器拥有独立MAC地址,在物理网络中表现为独立主机
- overlay:基于基于VXLAN实现,用于跨主机通信
例如,当访问宿主机的8080端口映射到容器时。请求会先到达宿主机,iptables NAT规则将流量转发到容器IP,数据通过docker0网桥进入容器,最终由容器内进程处理请求。